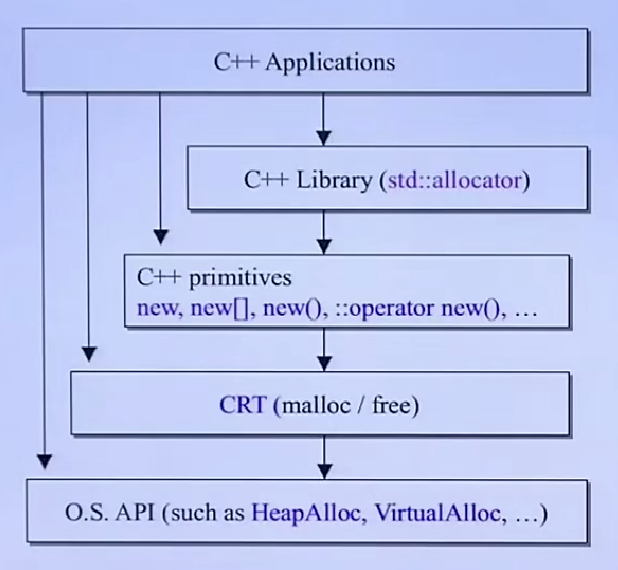
| malloc() |
free() |
C函数 |
不可 |
| new |
delete |
C++表达式 |
不可 |
| ::operator new() |
::operator delete() |
C++函数 |
可 |
| allocator::allocate()
| allocator::deallocate()
| C++标准库 |
可自由设计并与之搭配任何容器 |
#include <iostream>
#include <complex>
using namespace std;
int main() {
void* p1 = malloc(521);
free(p1);
complex<int>* p2 = new complex<int>;
delete p2;
void* p3 = ::operator new(512);
::operator delete(p3);
#ifdef _MSC_VER
// 以下两个函数都是non-static,一定要通过object调用,以下分配3个int空间
int* p4 = allocator<int>().allocate(3, (int*)0);
// 上面的 (int*)0 暂时没有用
// 通过 allocator<int>() 创建要给临时对象,执行临死对象的allocate方法
allocator<int>().deallocate(p4, 3);
// 通过 allocator<int>() 创建要给临时对象,执行临死对象的deallocate方法
#endif // _MSC_VER
#ifdef __BORLANDC__
// 以下两个函数都是non-static,一定要通过object调用,以下分配5个int空间
int* p4 = allocator<int>().allocator(5);
allocator<int>().deallocate(p4, 5);
#endif // __BORLANDC__
#ifdef __GNUC__
// 以下两个函数都是static,可通过全名调用,一下分配512bytes
void* p4 = alloc::allocate(512);
alloc::deallocate(p4, 512);
#endif // __GNUC__
return 0;
}
上述代码为四种内存分配的基本用法
class Complex {
public:
Complex(int x, int y) {
m_x = x;
m_y = y;
std::cout << "constructor Complex" << std::endl;
}
Complex() {
m_x = 0;
m_y = 0;
std::cout << "constructor Complex" << std::endl;
}
private:
int m_x;
int m_y;
};
void func_new() {
Complex* p1 = new Complex(1, 2);
delete p1;
// 等价于
Complex* p2;
try
{
void* mem = operator new(sizeof(Complex));
p2 = static_cast<Complex*>(mem);
p2->Complex::Complex(1, 2);
operator delete(p2);
// 这里直接调用构造函数的动作 只有编译器才可以这么写 自己写不同平台可能报错
}
catch (std::bad_alloc)
{
}
}
tip: 上述代码中说明了不可直接pc->Complex::Complex(1,2)方法,如果想直接调用构造函数可以运用placement new,写法是new(p)Complex(1,2)
// gcc 中 operator new的实现方式
void *operator new(std::size_t size) _THROW_BAD_ALLOC
{
if (size == 0)
size = 1;
void* p;
while ((p = ::malloc(size)) == nullptr)
{
// If malloc fails and there is a new_handler,
// call it to try free up memory.
std::new_handler nh = std::get_new_handler();
if (nh)
nh();
else
#ifndef _LIBCPP_NO_EXCEPTIONS
throw std::bad_alloc();
#else
break;
#endif
}
return p;
}
从上面的代码可以看到,new的实现方式就是调用了operator new方法,在强转之后执行了对应的构造函数
而operator new方法中,真正分配内存的是malloc方法
网上看到的资料
Complex* pc = new Complex(1, 2);
// ... some operation
delete pc;
// 编译器将delete转换成下面操作
pc->~Complex(); // 先析构
operator delete(pc); // 然后释放内存
上述为delete的操作,这里直接调用析构函数不会报错
void operator delete(void* ptr) noexcept
{
::free(ptr);
}
operator delete底层通过free释放内存
上述代码中pc->Complex::Complex(1, 2)直接执行构造函数没有报错,并不能表示我们可以都这么直接调用构造,下面代码就是一个反例
string* pstr = new string;
pstr->string::string();
pstr->~string();
delete pstr;
这里的代码会明显报错class std::basic_string<char> has no member named string
这里报错的原因是string本来的名字其实叫basic_string,是被typedef成string,所以string的构造函数应该是basic_string()才对
除了typedef导致构造函数名字不对的问题之外,编译器的严格程度不同也会出现报错,即存在平台差异性,所以不推荐手动调用构造函数
array new / array delete
Complex* pca = new Complex[3]; // 唤起三次构造函数
// ... some operation
delete[] pca; // 唤起三次析构
如果写的是delete而不是delete[],那么编译器只会执行一次析构函数,而不是三次,也就是说有两个对象的析构函数没有执行,如果对象中存在new操作,这样会导致无法执行delete进而导致内存泄漏
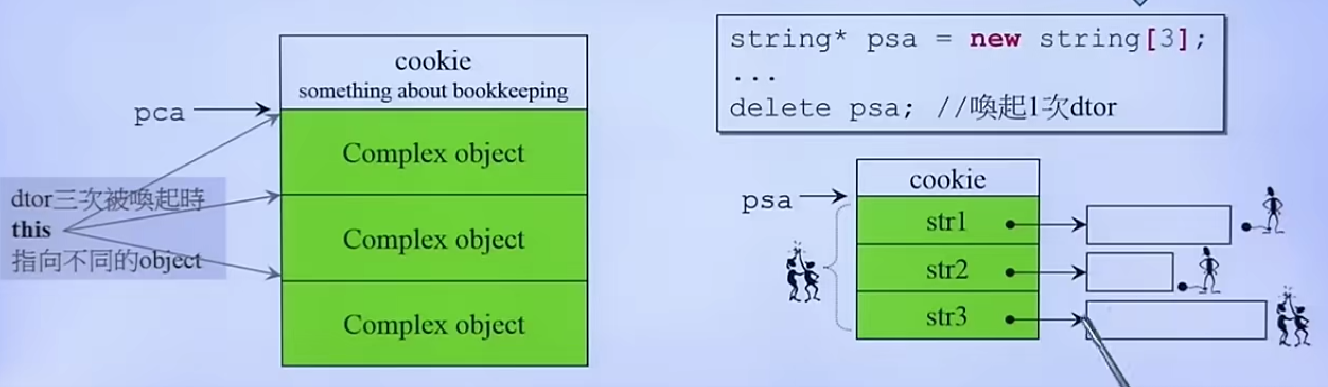
从上图中可以看到,new出的内存块除了包含三个Complex对象外,还包含一些cookie信息,这些信息帮助操作系统释放整块内存,而delete与delete[]区别仅仅在于数组中所有对象是否都执行析构
class A{
public:
int id;
A(): id(0) { std::cout << "default " << this << " " << this->id << std::endl; };
A(int i): id(i) { std::cout << this << " " << "int cons" << i << std::endl; }
~A() { std::cout << " ~ " << this << " " << this->id << std::endl; }
};
void test_placement_new() {
A* buf = new A[3]; // 调用A的默认构造函数,创建对象
A* tmp = buf;
for (int i = 0; i < 3; i++) {
new(tmp++)A(i); // placement new的写法,在tmp地址的构建A对象,调用A的构造函数
}
delete[] buf;
}
default 00A64CF4 0
default 00A64CF8 0
default 00A64CFC 0
00A64CF4 int cons0
00A64CF8 int cons1
00A64CFC int cons2
~ 00A64CFC 2
~ 00A64CF8 1
~ 00A64CF4 0
通过查看输出,可以发现这上述代码的执行顺序
placement new
placement new 允许我们将object建构于allocated memory(已经分配的内存)中- 没有
placement delete,因为placement new根本没有分配内存
因为是构建于已经分配的内存中,所以需要一个现成的被分配的内存空间的指针
#include <new>
void func(){
char* buf = new char[sizeof(Complex) * 3];
Complex* pc = new(buf)Complex(1, 2);
// ....
delete[] buf;
}
void func_1(){
Complex* pc = new(buf)Complex(1, 2);
// 上面一行代码 等价下面的代码
Complex* pc;
try{
void* mem = operator new(sizeof(Complex), buf);
pc = static_cast<Complex*>(mem);
pc->Complex::Complex(1, 2);
}
catch(std::bad_alloc){
}
}
// 下面为当 operator new的两个参数为size_t和void*的源码
void* operator new(size_t, void* loc){
return loc;
}
上面的代码使用了 placement new,它可以让你在已经分配好的内存上构造对象。placement new的语法是:new (address) (type) initializer。其中,address 是你指定的内存地址,type 是你要构造的对象的类型,initializer 是你要传递给对象构造函数的参数
定位 new 操作符的优点是可以提高性能和异常安全性,因为它不需要再次分配内存,而且可以在程序员控制的内存上创建对象。定位 new 操作符的缺点是需要手动调用对象的析构函数来释放资源,而且不能使用 delete 操作符来删除对象,只能删除分配给它们的内存。
分析上述代码可以发现
operator new(size_t, void* loc)什么都没做,因为此时loc是已经分配好了的内存地址,所以不需要再分配内存placement new其实就是执行了一次构造函数
C++分配内存的途径

一般来说,我们会重载类的Foo::operator new和Foo::operator delete,将对象的创建和内存分配自己来控制(通过自己控制可以减少内存块上的cookie的使用)
Foo*p = (Foo*)malloc(sizeof(Foo));
new(p)Foo(x);
// ...
p->~Foo();
free(p);
当然也可以重载全局::operator new / ::operator delete
// 测试重写代码
void* myAlloc(size_t size){
return malloc(size);
}
void myFree(void* ptr){
return free(ptr);
}
inline void* operator new(size_t size){
cout << "my new" << std::endl;
return myAlloc(size);
}
inline void* operator new[](size_t size){
cout << "my new[]" << std::endl;
return myAlloc(size);
}
inline void operator delete(void* ptr){
cout << "my delete" << std::endl;
myFree(ptr);
}
inline void operator delete[](void* ptr){
cout << "my delete[]" << std::endl;
myFree(ptr);
}
更常见的写法是类中重载
class Foo {
public:
int _id;
long _data;
std::string _str;
public:
Foo() : _id(0) { std::cout << "default ctor " << this << " " << this->_id << std::endl; }
Foo(int i): _id(i) { std::cout << "ctor " << this << " " << this->_id << std::endl; }
virtual ~Foo() { std::cout << "dtor " << this << std::endl; }
static void* operator new(size_t size);
static void operator delete(void* pdead, size_t size);
static void* operator new[](size_t size);
static void operator delete[](void* pdead, size_t size);
};
void* Foo::operator new(size_t size) {
Foo* p = (Foo*)malloc(size);
std::cout << "my alloc Foo " << p << std::endl;
return p;
}
void Foo::operator delete(void* pdead, size_t size) {
std::cout << "my delete " << pdead << std::endl;
free(pdead);
}
void* Foo::operator new[](size_t size) {
Foo* p = (Foo*)malloc(size);
std::cout << "my alloc Foo " << p << std::endl;
return p;
}
void Foo::operator delete[](void* pdead, size_t size) {
std::cout << "my delete " << pdead << std::endl;
free(pdead);
}
int main() {
std::cout << sizeof(Foo) << std::endl;
Foo* p = new Foo(7);
delete p;
Foo* pArray = new Foo[5];
delete[] pArray;
return 0;
}
40
my alloc Foo 00C2DA78
ctor 00C2DA78 7
dtor 00C2DA78
my delete 00C2DA78
my alloc Foo 00C30110
default ctor 00C30114 0
default ctor 00C3013C 0
default ctor 00C30164 0
default ctor 00C3018C 0
default ctor 00C301B4 0
dtor 00C301B4
dtor 00C3018C
dtor 00C30164
dtor 00C3013C
dtor 00C30114
my delete 00C30110
但是,如果使用::new和::delete则会绕过类定义的operator new / operator delete方法,转而执行全局的new / delete
int main() {
std::cout << sizeof(Foo) << std::endl;
Foo* p = ::new Foo(7);
::delete p;
Foo* pArray = ::new Foo[5];
::delete[] pArray;
return 0;
}
分配内存
Foo* p = new Foo();
delete p;
上述代码等价于下面的代码,原理不再解释
Foo* p = (Foo*)operator new(sizeof(Foo));
new(p) Foo(x);
p->~Foo();
operator delete (p);
operator new 本质上还是调用 malloc 来分配内存,虽然这个过程一般来说很快,但是如果可以减少 malloc 调用的次数,一定程度上可以加快程序运行效率
那么我们可以一开始就分配一个很大的内存,然后切成一个个小块分配给具体的对象,这样就只用 malloc 一次,然后我们手动对内存分块

还有一点就是这样子可以减少 cookie 的量,每一次 malloc 除了分配指定大小的内存之外,还在内存块前后分别额外申请了内存用于存放 cookie,cookie中的信息用于表示内存是否被分配以及分配的大小等信息
cookie 并不是C++语言标准中的术语

如果是一开始自己申请一大块内存,手动切割内存可以减少 cookie 的量,从而提升内存的使用率
基于上面的想法,我们得到了如下的设计
#include <cstddef>
#include <iostream>
class Screen {
public:
Screen(int x): i(x) {};
int get() { return i; }
static void* operator new(size_t);
static void operator delete(void*, size_t);
private:
Screen* next;
static Screen* freeStore;
static const int screenChunk;
private:
int i;
};
Screen* Screen::freeStore = nullptr;
const int Screen::screenChunk = 24;
void* Screen::operator new(size_t size)
{
Screen* p = nullptr;
if (!freeStore) {
// linked list 为空 需要申请一大块内存
size_t chunk = screenChunk * size;
freeStore = p = reinterpret_cast<Screen*>(new char[chunk]);
// &freeStore[screenChunk - 1] 表示 freeStore 数组中最后一个 Screen 的内存地址 p 指向最后一个 Screen 时表示遍历结束
for (; p != &freeStore[screenChunk - 1]; ++p) {
p->next = p + 1;
}
p->next = nullptr;
}
p = freeStore;
freeStore = freeStore->next;
return p;
}
void Screen::operator delete(void* p, size_t)
{
(static_cast<Screen*>(p))->next = freeStore;
freeStore = static_cast<Screen*>(p);
}
int main() {
std::cout << sizeof(Screen) << std::endl;
size_t const N = 100;
Screen* p[N];
for (int i = 0; i < N; ++i) {
p[i] = new Screen(i);
}
for (int i = 0; i < 10; ++i) {
std::cout << p[i] << std::endl;
}
for (int i = 0; i < N; ++i) {
delete p[i];
}
return 0;
}
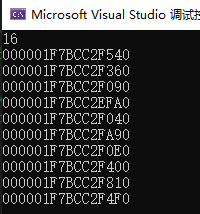
在自定义 opeator new 和 operator delete 之前,连续申请100个 Screen,每个对象的地址信息,可见虽然是连续申请的对象,但是地址之间插值并不是 16,可见有 cookie 存在
在使用自定义 operator new 和 operator delete 之后,Screen 对象地址连续,并没有被 Cookie 占用
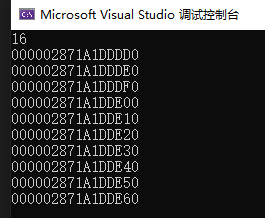
这里 Screen 使用了链表来连接整个大内存空间中的 Screen 对象
有一个问题就是 Screen 对象中仅仅存在一个 int i 的属性大小是 8 个字节,但是为了自己分配内存空间需要额外定义 Screen* next 指针,指针也占用 8 个字节,浪费了 50% 的空间
为了节省指针导致的内存浪费,可以使用 union 来处理
class Airplane {
private:
struct AirplaneRep {
unsigned long miles;
char type;
};
private:
union {
AirplaneRep rep; // 指针对使用中的 objects
Airplane* next; // 指针对 fire list 中的object
};
public:
unsigned long getMiles() { return rep.miles; }
char getType() { return rep.type; }
void set(unsigned long m, char t) {
rep.miles = m; rep.type = t;
}
public:
static void* operator new (size_t size);
static void operator delete (void* deadObject, size_t size);
private:
static const int BLOCK_SIZE;
static Airplane* headOfFreeList;
};
Airplane* Airplane::headOfFreeList = nullptr;
const int Airplane::BLOCK_SIZE = 512;
void* Airplane::operator new(size_t size) {
// 如果大小有误 转交 ::operator new
if(size!=sizeof(Airplane)) {
return ::operator new(size);
}
Airplane* p = headOfFreeList;
if (p) {
headOfFreeList = p->next;
}
else {
// free list 为空 需要申请初始内存
Airplane* newBlock = static_cast<Airplane*>(::operator new(BLOCK_SIZE * sizeof(Airplane)));
// 将小块串成 free list
// 但跳过 #0 因为它将作为本次返回结果
for (int i = 1; i < BLOCK_SIZE - 1; i++)
{
newBlock[i].next = &newBlock[i + 1];
}
newBlock[BLOCK_SIZE - 1].next = nullptr;
p = newBlock;
headOfFreeList = &newBlock[1];
}
return p;
}
void Airplane::operator delete(void* p, size_t size)
{
if (p == nullptr) {
return;
}
if (size != sizeof(Airplane)) {
::operator delete(p);
return;
}
Airplane* carcass = static_cast<Airplane*>(p);
carcass->next = headOfFreeList;
headOfFreeList = carcass;
}
Airplane 的 sizeof 大小为 8
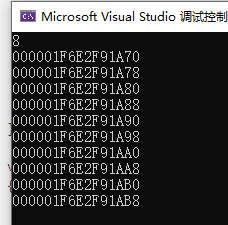
为了实现自己的内存分配,我们给 Airplane 和 Screen 两个类重写了 operator new 和 operator delete
那么如果我有100个类甚至1000个类又该如何?我们不能给每个类都重写 operator new 和 operator delete 吧?关键是每个类的写法相似,功能相同,所以得想一个办法把自定义内存分配的操作从对象中剥离出来
所以我们需要一个 allocator 分配器对象
#include <cstddef>
#include <iostream>
class MyAllocator {
private:
struct obj
{
struct obj* next;
};
public:
void* allocate(size_t);
void deallocate(void*, size_t);
private:
obj* freeStore = nullptr;
const int CHUNK = 5; // 标准库是20
const int min_size = 8;
};
void* MyAllocator::allocate(size_t size)
{
obj* p = nullptr;
size = size > min_size ? size : min_size;
if (!freeStore) {
size_t chunk = CHUNK * size;
freeStore = p = (obj*)malloc(chunk);
if (p == nullptr) {
return nullptr;
}
// 连接内存块
for (int i = 0; i < CHUNK - 1; ++i) {
p->next = (obj*)((char*)p + size);
p = p->next;
}
p->next = nullptr; // last
}
p = freeStore;
freeStore = freeStore->next;
return p;
}
void MyAllocator::deallocate(void* p, size_t)
{
// 将 p 收回插入 free list 前端
((obj*)p)->next = freeStore;
freeStore = (obj*)p;
}
class Goo {
public:
long L;
static MyAllocator myAlloc;
public:
Goo(long l) : L(l) {}
static void* operator new(size_t size) {
return myAlloc.allocate(size);
}
static void operator delete(void* pDead, size_t size) {
myAlloc.deallocate(pDead, size);
}
};
MyAllocator Goo::myAlloc;
void foo_myALlocator() {
std::cout << sizeof(Goo) << std::endl;
size_t const N = 4;
Goo* p[N];
for (int i = 0; i < N; ++i) {
p[i] = new Goo(i);
}
for (int i = 0; i < 3; ++i) {
std::cout << p[i] << std::endl;
}
for (int i = 0; i < N; ++i) {
delete p[i];
}
}
int main() {
foo_myALlocator();
return 0;
}
这里需要注意的是自定义的 MyAllocator 有一个属性 min_size = 8,在 x64 的平台上指针占 8个字节,上述代码的 Goo 对象占 4个字节,也就是说在地址运算的时候会将前后两个 Goo 对象的内存合并为一个地址,最后出现错误
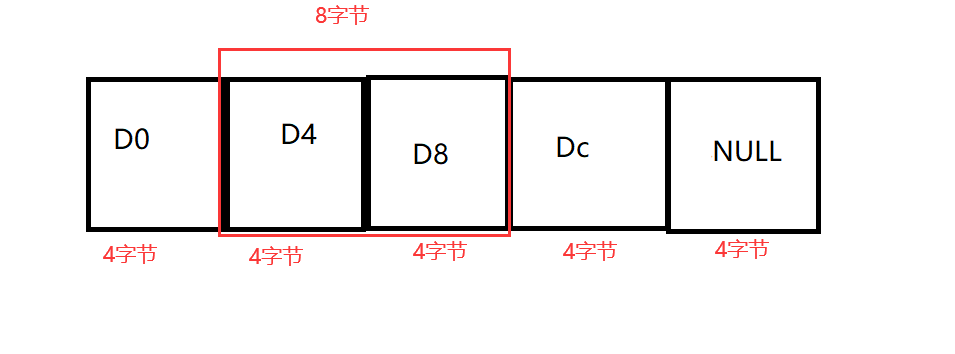
以上图为例,一格黑色方块就是一个 Goo 对象的大小4字节,是提前为未来的 Goo 创建出来的内存空间。理论上来说第一格内存地址为 D0,其 next 指针指向 D4,但是实际运行时由于地址为 8字节,所以第一格的 next 指针的值其实是 D0D4,而这个地址其实是一个未知地址,最后导致运行报错
上述代码其实也很明显,将 Goo 的内存块 cast 成 Obj 对象来管理空闲空间,以此达到节省内存空间的效果。当内存块需要被使用时,其会从空闲链表中移出并设置,此时就与链表无关的,所以也不用管 next 的值。等到 Goo 被 delete 时,其会从 Goo 再次转为 Obj 链表节点,这时也不用管 Goo 对象的值是多少,因为此时 Goo 对象已经无效了
通过上面的 MyAllocator 的内存分配器可以给其他任意类型的对象使用,对象无需再关注内存如何分配,而是仅仅需要引入 MyAllocator 并且在 operator new 和 operator delete 中使用即可
然后稍微使用宏来优化一下
#define DECLARE_POOL_ALOC() \
public: \
static void* operator new(size_t size) { return myAlloc.allocate(size); } \
static void operator delete(void* pDead, size_t size) { myAlloc.deallocate(pDead, size); } \
protected:\
static MyAllocator myAlloc;
#define IMPLEMENT_POOL_ALLOC(class_name) MyAllocator class_name::myAlloc;
class Goo {
public:
long L;
public:
Goo(long l) : L(l) {}
DECLARE_POOL_ALOC()
};
IMPLEMENT_POOL_ALLOC(Goo);
如此一来,对于所有的类来说仅仅使用两个宏就可以实现内存池的功能
new handler
当 operator new 无法给你分配出所需的 memory 时,会抛出 std::bad_alloc exception 异常,某些旧的编译器则是返回0
当然你也可以指定不要抛出异常
new(std::nothrow) int;
抛出异常之前会先(不止一次)调用一个可由 client 指定的 handler,下面的带啊吗是 new handler 的形式和设定方法
typedef void (*new_handler)();
new_handler set_new_handler(new_handler p) thro();
实际操作如下
#include <new>
void newErr(void)
{
cout << "new error" << endl;
system("pause");
exit(-1);
}
set_new_handler(newErr);
根据 operator new C++ 源码来看,在 malloc 申请内存失败之后,会调用 _callnewh 函数,该函数就是 call new hanlder 的缩写
这样做其实就是让用户判断一下有没有补救措施,然后再调用一次 malloc ,说不定就成功了
一般在 new handler 中会进行一些操作
- 检查可释放内存,提前释放掉,这样内存多了获取就可以
new 成功了
- 调用
abort() 或者 exit() 主动退出并且弹出警告信息
void* __CRTDECL operator new(size_t const size)
{
for (;;)
{
if (void* const block = malloc(size))
{
return block;
}
if (_callnewh(size) == 0)
{
if (size == SIZE_MAX)
{
__scrt_throw_std_bad_array_new_length();
}
else
{
__scrt_throw_std_bad_alloc();
}
}
// The new handler was successful; try to allocate again...
}
}
不同的平台和版本可能有差异
std::allocator
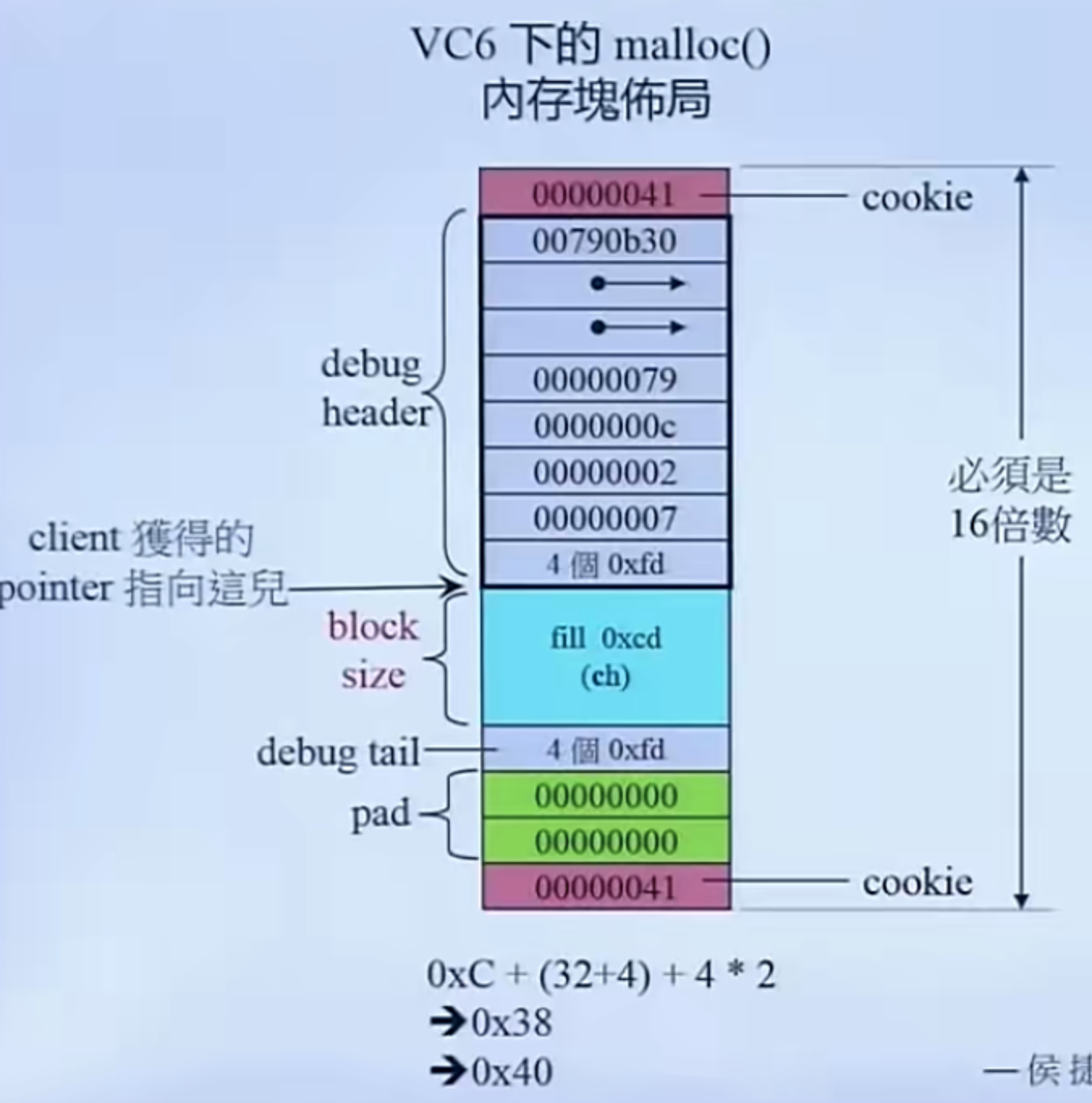
上图是 vc6 下的 malloc
| 颜色 |
作用 |
| 红色 |
Cookie 标记的内存区块大小 |
| 灰色 |
固定内容 用于 Debug |
| 绿色 |
pad 区域,用于判断整块内存是否16的倍数,不是的话用 pad 区域填充 |
| 蓝色 |
真正对象会用到的内存空间 |
参考上图,当使用 malloc 申请内存的时候,会额外申请一些内存空间用于缓存(Cookie)一些信息
Cookie 主要是记录区块有多大
这些缓存信息带着一些额外的内存开销,如果申请一些比较小的内存,那么缓存信息所浪费的比值就比较大;反之如果申请内存较大,那么缓存信息所浪费的内存空间比值较小
尤其是在软件开发中,我们每次申请的对象内存都不会太大,但是这种对象会很多,所以内存浪费就很明显
不同编译器下所带的标准库中的分配器的实现方式可能都不相同
下面的代码是 macos 中 xcode 中 std::allocator 的实现方法
template <class _Tp>
class _LIBCPP_TEMPLATE_VIS allocator
: private __non_trivial_if<!is_void<_Tp>::value, allocator<_Tp> >
{
static_assert(!is_volatile<_Tp>::value, "std::allocator does not support volatile types");
public:
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef _Tp value_type;
typedef true_type propagate_on_container_move_assignment;
typedef true_type is_always_equal;
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
allocator() _NOEXCEPT = default;
template <class _Up>
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
allocator(const allocator<_Up>&) _NOEXCEPT { }
_LIBCPP_NODISCARD_AFTER_CXX17 _LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
_Tp* allocate(size_t __n) {
if (__n > allocator_traits<allocator>::max_size(*this))
__throw_bad_array_new_length();
if (__libcpp_is_constant_evaluated()) {
return static_cast<_Tp*>(::operator new(__n * sizeof(_Tp)));
} else {
return static_cast<_Tp*>(_VSTD::__libcpp_allocate(__n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp)));
}
}
#if _LIBCPP_STD_VER > 20
// 特殊处理
#endif
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_SINCE_CXX20
void deallocate(_Tp* __p, size_t __n) _NOEXCEPT {
if (__libcpp_is_constant_evaluated()) {
::operator delete(__p);
} else {
_VSTD::__libcpp_deallocate((void*)__p, __n * sizeof(_Tp), _LIBCPP_ALIGNOF(_Tp));
}
}
#if _LIBCPP_STD_VER <= 17 || defined(_LIBCPP_ENABLE_CXX20_REMOVED_ALLOCATOR_MEMBERS)
// 被 C++ 20 移除的一些内容
#endif
};
稍微扫一下上面的代码,很明显可以定位到 allocate 函数和 deallocate 函数, 根据函数的实现其本质也很简单就是调用 ::operator new 和 ::operator delete
所以某些情况下 allocator 其实几乎啥都没做,没有做内存管理,而是直接调用全局的 new 和 delete