
现代C++.md 18 KB
现代 C++
基于对象基础
一个类基本包括数据成员(字段) + 函数成员
class Point {
int x;
int y;
static int xx;
void Process() {
// do something
Process2(100);
}
void Process2(int x) {
// do something
}
static void Process3() {
xx++;
}
};
int Point::x = 0;
int main() {
Point pt;
pt.Process();
}
对于编译器来说,它可以这么理解上述代码
struct Point {
int x;
int y;
static int xx;
}
int Point::xx = 0;
void Process(Point* this) {
// do something
this->Process2(100);
}
void Process2(Point* this, int x) {
// do something
}
void Process3() {
Point::xx++;
}
将所有的成员函数都定义为,上述这种普通函数,然后给每个函数额外添加一个 Point* 的参数,用于指向执行该函数的对象
因为 Process3 是一个 static 函数,所以无法访问非 static 的成员属性,这个时候 Process3 就不用添加 Point*
相对来说,使用 C++ 的定义 class 的方法编写代码,可以将行为(函数)和状态(属性)结合起来进行编写
内存对齐
对于下面两个类的定义,虽然属性相同,但是对象内存大小占用却不相同
#pragma pack(8)
class P1 {
char a1;
int x;
char a2;
};
class P2 {
char a1;
char a2;
int x;
};
// sizeof(P1) 12
// sizeof(P2) 8
在 C++ 中存在内存对齐,使用内存对齐可以优化 CPU 存储数据效率、避免数据截断。对按对齐系数(4、8字节)整倍数进行对齐
可以使用
#pragma pack(4)控制对齐大小
- 内存对齐规则
- 成员对齐:每个成员的地址必须是其自身大小或
#pragma pack(n)设置值的较小值的倍数 - 结构体总大小:必须是所有成员中最大对齐值的整数倍
- 填充字节:编译器在成员之间插入空隙(padding),以满足对齐要求
- 成员对齐:每个成员的地址必须是其自身大小或
对于 class P1 来说
- char a1
- 大小:1 字节
- 对齐要求:min(1, 8) = 1
- 地址范围:0
- int x
- 大小:4 字节
- 对齐要求:min(4, 8) = 4
- 起始地址必须是 4 的倍数
- 当前地址是 1,需填充 3 字节(地址 1-3),使 x 从地址 4 开始
- 地址范围:4-7
- char a2
- 大小:1 字节
- 对齐要求:1
- 直接放在 x 后面,地址 8
当前总大小:0-8(共 9 字节)。结构体总大小必须是最大对齐值(4)的整数倍。9 向上取整到最近的 4 的倍数是 12,因此末尾填充 3 字节
最大对齐值:最大对齐值是结构体中所有成员的对齐值中的最大值,成员的对齐值 =
min(成员自身大小, #pragma pack(n) 设置的值)
最终内存布局
| a1 (1) | padding (3) | x (4) | a2 (1) | padding (3) |
对于 class P2 来说
- char a1
- 地址范围:0
- char a2
- 地址范围:1
- int x
- 对齐要求:4
- 当前地址是 2,需填充 2 字节(地址 2-3),使 x 从地址 4 开始
- 地址范围:4-7
当前总大小:0-7(共 8 字节)。8 已经是最大对齐值(4)的整数倍,无需额外填充
最终内存布局
| a1 (1) | a2 (1) | padding (2) | x (4) |
通过对比 P1 和 P2 的内存,可以得到结论:大内存属性放前面,小内存属性放后面
那么,如果在类中添加一个函数,会影响这个对象大小吗?
class Point {
int x;
int y;
void Process() {}
};
// sizeof(Point) 8
通过上面的代码可以发现,sizeof(Point) 的大小还是 8,函数定义并没有增加 Point 的大小
这是因为前面解释过编译器如何理解 C++ 对象的,就是一个数据结构体 + 全局函数
也就是说,Point 对象被解析成了下面这样, Process 被解析成了全局函数,占用的是代码段大小,不影响对象大小
struct Point { int x; int y;};
Process(Point* this)
{
// do something
}
但是,如果是下面定义的对象,又不一样,Point1 对象有一个虚函数 Process2,需要一个指针指向虚函数表,所以 Point1 额外需要一个虚函数指针,因此 sizeof(Point1) 大小是 16
指针的大小根据平台不同,可能是 4,也可能是 8
class Point1 {
int x;
int y;
void Process() {}
virtual void Process2() {}
};

以上图为例,如果一个类有虚函数,那么这个类对象在内存中第一个属性是一个指针,指向这个类的虚函数表
既然知道这个类的第一个属性是一个指针,是否可以通过指针获取到虚函数表,然后获取虚函数表的第一个函数并执行它呢?
tip: 下面的例子可能在 MSVC 中运行失败,因为 MSVC 的虚函数表的第一位存储着 type_info 也就是类的类型信息
#include <iostream>
using namespace std;
class Point1 {
int x;
int y;
virtual void Process2(int InParam) { std::cout << "hello world " << InParam << std::endl; }
};
typedef void(*Fun)(Point1*, int);
int main()
{
auto a = new Point1();
std::cout << sizeof(int) << " " << sizeof(long) << " " << sizeof(void*) << std::endl;
Fun pfun = (Fun)*((long *)*(long *)(a));
pfun(a, 4);
delete a;
return 0;
}
这里使用
long*而不是int*是因为我机器上指针大小是 8 与long的大小相同
通过 *(long *)a 将对象 a 从 Point* 强转成 long*,然后对其取地址,得到虚函数表的首地址
将虚函数表的首地址强转成 long* 并对其取地址,得到第一个虚函数的指针,再将其强转成 void *(int) 的函数指针,就可以执行它
为什么要定义
Fun为void(*)(Point*, int),还记得之前说过编译器如何对 C++ 类的函数做处理的吗?
继承的内存模型
- 单继承的内存结构
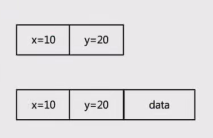
- 多继承的内存结构

- 菱形继承

#include <iostream>
class Base {
int x;
};
class A : public Base {
int XX;
};
class B : public Base {
int YY;
};
class C : public A, public B {
int ZZ;
};
int main()
{
std::cout << "sizeof(Base) = " << sizeof(Base) << std::endl; // 4
std::cout << "sizeof(A) = " << sizeof(A) << std::endl; // 8
std::cout << "sizeof(B) = " << sizeof(B) << std::endl; // 8
std::cout << "sizeof(C) = " << sizeof(C) << std::endl; // 20
return 0;
}
根据上面的例子,不难发现, 类 C 的大小是两个父类的大小的和 + 自己属性 ZZ 的大小,也就是说 C 中有两份 Base 数据
传统菱形继承存在很多问题,包括命名冲突、冗余数据等
为了解决菱形继承的问题,C++ 提出了 虚继承
class Base {
int x;
};
class A : public virtual Base {
int XX;
};
class B : public virtual Base {
int YY;
};
class C : public A, public B {
int ZZ;
};
这里 Base 就是一个虚基类, 不论虚基类再继承体系中出现多少次,在派生类中只包含一份虚基类的成员
sizeof(Base) // = 4
sizeof(A) // = 16
sizeof(B) // = 16
sizeof(C) // = 40
注意这里 A 和 B 的内存大小,增加了 8 个 字节,也就是一个指针的大小
很明显,虚基类和虚函数一样,增加了个一个指针,指向这个类的虚基类表,同时由于多了一个指针,需要内存对齐,所以 sizeof(A) 的内存大小是 4 + 8 + 4(空白内容)
════════════ Base ════════════
┌───────────┐
│ x │ 4字节
└───────────┘
════════════ A ════════════
┌───────────┬───────────┬───────────┬───────────┐
│ vbase_ptr (8字节) │ XX (4) │ padding (4) │
└───────────┴───────────┴───────────┴───────────┘
════════════ C 的内存布局 ════════════
┌───────────┬───────────┬───────────┬───────────┐ ← A部分
│ A的虚基类指针 │ XX │ padding │
├───────────┼───────────┼───────────┼───────────┤ ← B部分 ← C自身
│ B的虚基类指针 │ YY │ ZZ │
├───────────┼───────────┼───────────┴───────────┤ ← 虚基类Base
│ x │ padding │
└───────────┴───────────┘
此时 C 的内存大小是 Base::x + A::XX + A的虚基类表指针 + B::XX + B的虚基类表指针 + C::ZZ
#include <iostream>
class Base {
public:
int x;
};
class A : public virtual Base {
public:
int XX;
};
class B : public virtual Base {
public:
int YY;
};
class C : public A, public B {
public:
int ZZ;
};
int main()
{
auto t = new C();
t->x = 10;
t->XX = 11;
t->YY = 12;
t->ZZ =13;
std::cout << (*(int*)((void *)t + 8)) << std::endl; // 11
std::cout << (*(int*)((void *)t + 16 + 8)) << std::endl; // 12
std::cout << (*(int*)((void *)t + 16 + 8 + 4)) << std::endl; // 13
std::cout << (*(int*)((void *)t + 16 + 16)) << std::endl; // 10
std::cout << sizeof(C) << std::endl; // 40
return 0;
}
Base实例被放在整个对象末尾,通过指针偏移访问
空类的内存模型
class A{
};
// sizeof(A) = 1
对于空类 A,它的内存大小 sizeof 是多少呢?
答案是 1
为什么一个空类的大小是 1 呢?
在 C++ 中,只要是一个对象,它一定是有大小的,否则怎么给他分配内存、怎么通过寻址查找对象呢?
所以,对于一个编译器来说,如果这个类没有任何属性,编译器会自动给他添加一个 char 属性,用于分配内存
那对下面这个情况呢?
class A {};
class B : public A {
int X;
};
class C {
A a;
int X;
};
class D : public A {};
// sizeof(B) = 4
// sizeof(C) = 8
// sizeof(D) = 1
- 对于 B 来说,已经存在需要占用内存的属性了,不需要再为了分配内存而给 B 的父类 A 额外添加一个 char
- 简称 空基类优化
- 对于 C 来说,
A a仍然需要一个 char 类区分内存,再加上内存对齐,所以占 8 字节
除了空基类的情况,一般来说继承和组合的方式构成的新类内存大小相同
绝大部分情况,组合优于继承
除此之外,对于空基类还有一些使用方法,比如下面这种写法
class A {
public:
void ReleaseImpl() {}
};
class B : private A {
public:
void Release() { ReleaseImpl(); }
private:
int x;
};
class C {
public:
void Release() { a.ReleaseImpl(); }
private:
A a;
int x;s
}
上述代码,对比类 B 和类 C 的实现方式,这个时候更倾向于使用类 B 而不是类 C
- 更小的内存占用
- 使用
private的继承方式,不会暴露内部接口
除此之外,还有一些使用方法
#include <iostream>
class A1 {
public:
void ReleaseImpl() { std::cout << "A1" << std::endl; }
};
class A2 {
public:
void ReleaseImpl() {std::cout << "A2" << std::endl; }
};
template<typename ToolBase = A1>
class B : private ToolBase {
public:
void Release() { ToolBase::ReleaseImpl(); }
};
int main()
{
auto b = B<A2>();
auto c = B<A1>();
auto d = B();
b.Release();
c.Release();
d.Release();
return 0;
}
结合模板的使用,能够将一些功能拆分到不同的类中,并通过模板选择不同的继承类,来修改程序执行过程中的一些内容
比如,根据继承的基类不同,资源释放的方式也可能不同
类的类型信息
#include <iostream>
class A {
public:
int X;
double Y;
virtual ~A(){}
};
class B : public A {
};
int main()
{
A* a = new A();
A* b = new B();
const std::type_info& t1 = typeid(*a);
const std::type_info& t2 = typeid(*b);
std::cout << t1.name() << std::endl;
std::cout << t2.name() << std::endl;
B* c = dynamic_cast<B*>(a); // nullptr
B* d = dynamic_cast<B*>(b); // success
std::cout << t1 == t2 << std::endl; // false
return 0;
}
a的编译时类型是A,实际类型是A
b的编译时类型时A,实际类型时B
根据编译器不同,type_info 存储的位置也不相同
- MSVC 存储在类型关联的虚函数表中
- GCC/Clang 存储在独立的内存区域中
也就是说,如果使用 MSVC 运行前面的通过虚函数表直接执行虚函数的例子是不能正常运行的,因为 MSVC 的虚函数表存储着额外的信息
类的析构要定义为虚函数
#include <iostream>
class A {
public:
~A(){
std::cout << "~A" << std::endl;
}
};
class B : public A {
public:
~B() {
std::cout << "~B" << std::endl;
}
};
class C : public B {
public:
~C() {
std::cout << "~C" << std::endl;
}
};
int main()
{
A* b = new C();
delete b;
return 0;
}
对于上述代码,理论上我们期望的输出结果是 ~C ~B ~A,因为 b 的实际类型是 C,根据继承规则应该从子类到父类逐步析构
但是实际上的输出结果是 ~A,也就是说并没有执行 C 和 B 的析构
如果类 B 或者类 C 中申请了内存,在析构函数中释放申请的内存,遇到上述情况就会出现析构函数不执行,进而导致内存泄漏的问题
为了解决这个隐患,通常都是讲析构函数定义为虚函数
class A {
public:
virtual ~A(){
std::cout << "~A" << std::endl;
}
};
左值右值
定义
- 左值:命名对象、可取地址、可赋值
- 基本变量类型、数组、数组元素
- 字符串字面量
"success"[0]和&"success"可以正常编过 - 对象变量、对象成员
- 函数(可取地址)
- 返回左值的表达式
- 右值:无名、无法取地址、不可赋值
- 各种临时变量(函数返回值)、字符串临时变量
- 除字符串外的其他基本类型字面量
- lambda 表达式
- 运算符表达式
#include <string>
#include <iostream>
#include <utility>
using namespace std::literals;
template<typename T>
void log(T&& in)
{
std::cout << "log && " << in << std::endl;
}
template<typename T>
void log(T& in)
{
std::cout << "log & " << in << std::endl;
}
void process(int&& data);
void process(int& data);
void process(int&& data)
{
std::cout << "process && " << std::endl;
process(data);// 记得前置声明 void process(int& data) ,这里的 data 是个左值,不前置声明找不到可以匹配的函数
}
void process(int& data)
{
std::cout << "process & " << std::endl;
}
int main()
{
int a = 0;
log(1); // 右值
log(a = 30); // 左值
log("123"); // 左值
log("456"s); // 右值 "456"s 等于 string("456") 得到的是一个临时变量
std::cout << &"success" << std::endl;
int x = 1, y = 2;
process(x+y); //
return 0;
}
msvc 编不过,clang 可以
可以注意以下 process 函数,虽然 process(x+y) 触发的是右值,但是在函数中,data 其实是个左值
移动
- 左值:有身份,不呢个移动
- 纯右值:没身份,可移动
- 将亡值:有身份,可以移动
当源对象是一个左值,移动左值并不安全,因为左值后续持续存在,可能被引用,虽然可以将左值强制转换为右值,但是需要自负安全
当源对象是一个右值,移动很安全
void func(TestCls&& in);
上述代码,形参 in 到底是右值还是左值?
- 对函数调用者来说,
in是一个右值引用,要传递优质 - 对函数内部来说,
in是一个左值引用(可以取地址)
TestCls a1(1, 2);
TestCls a2 = a1; // 左值源 拷贝构造
a1 = a2; // 左值源 拷贝赋值
a1 = std::move(a2); // 移动赋值
// a2.process(); // 危险操作
std::move转为右值
一般来说,一个对象被 std::move 之后,这个对象被认定为无效对象,后续代码中不应再次使用,所以在 std::move 之后仍然执行 a2.process() 是危险操作,可能导致不确定后果
TestCls GetTestCls()
{
TestCls a1(1, 2);
return a1;
// 编译器自动优化为 return std::move(a1);
}
TestCls a2 = GetTestCls(); // 不触发任何构造 复制初始化,但可能被优化
TestCls a3(GetTestCls()); // 不触发任何构造 直接初始化
a2 = GetTestCls(); // 触发移动赋值,此时 a2 已经构造完毕,无法触发优化
上述代码,GetTestCls 函数返回值是一个临时对象,在接收的时候触发的是移动构造
上述代码,TestCls a3(GetTestCls()) 不会触发任何构造,这是因为 C++ 的返回值优化,编译器优化直接构造对象到目标内存,消除临时对象
- 返回值优化(RVO):编译器优化直接构造对象到目标内存,消除临时对象
- 命名返回值优化(NRVO):针对命名局部变量返回时的优化(C++17 起部分场景被强制要求)
针对 TestCls a(GetTestCls()) 预期行为是构建临时对象,调用移动构造。实际是编译器直接在 a 对象的内存位置构造对象,完全跳过了拷贝、移动构造
针对 TestCls a2 = GetTestCls() 从 C++17 开始强制要求进行拷贝省略,等同于直接构造,无需任何拷贝、移动操作
| 构造表达式 | C++ 标准 | 是否触发拷贝、移动构造 | 原因 |
|---|---|---|---|
| TestCls a(GetTestCls()) | <C++17 | 无 | RVO 优化 |
| ≥C++17 | 无 | 强制拷贝省略 | |
| TestCls a2 = GetTestCls() | <C++17 | 无 | 拷贝省略优化 |
| ≥C++17 | 无 | 强制拷贝省略 |
赋值规则
左值、左值引用、右值、右值引用的赋值规则
| & | const & | && | const && | |
|---|---|---|---|---|
| 左值 | 可以 | 可以 | ||
| const 左值 | 可以 | |||
| 右值 | 可以 | 可以 | 可以 | |
| const 右值 | 可以 | 可以 |