
 nicetry12138
30df15c521
feat: 添加贴图解释
nicetry12138
30df15c521
feat: 添加贴图解释
|
1 rok temu | |
|---|---|---|
| .. | ||
| Image | 1 rok temu | |
| src | 1 rok temu | |
| README.md | 1 rok temu | |
README.md
DirectX学习
创建窗口项目
直接使用 visual studio 创建空白项目,并创建 WinMain.cpp 作为程序入口
由于设置的是窗口系统,所以不能使用 main 作为入口函数,而是 WinMain
#include <Windows.h>
int WINAPI WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdSHow) {
while (true)
{
// 防止程序结束 用 while 阻塞函数
}
return 0;
}
根据文档解释,WinMain 函数的参数分别表示如下几个
hInstance是 实例的句柄 或模块的句柄。 当可执行文件加载到内存中时,操作系统使用此值来标识可执行文件或 EXE。 某些 Windows 函数需要实例句柄,例如加载图标或位图hPrevInstance没有任何意义。 它在 16 位 Windows 中使用,但现在始终为零pCmdLine以 Unicode 字符串的形式包含命令行参数nCmdShow是一个标志,指示主应用程序窗口是最小化、最大化还是正常显示
nCmdShow的使用,文档中也有解释
至于 WinMain 函数返回值,一般来说操作系统不使用返回值,但是可以使用该值将状态代码传递给另一个程序
一般来说返回 0 表示没有任何问题
至于 WINAPI 和 CALLBACK 宏
#define CALLBACK __stdcall
#define WINAPI __stdcall
#define WINAPIV __cdecl
一般来说
WINAPI指的是Windows API使用的一种调用约定。通常用于定义API函数,很多Windows API都这样CALLBACK常用于回调函数,例如事件处理或窗口处理函数(如WindowProc)。这确保这些函数能与发出回调的 Windows 操作系统兼容
使用 __stdcall 调用约定意味着参数从右至左被推送到堆栈上,且函数自己清理堆栈。这对于减少应用程序中的错误非常有用,因为堆栈管理是自动的
除了 __stdcall 之外,还有 __cdecl 和 __fastcall
__cdecl: 参数同样是从右至左推入堆栈,但是调用者清理堆栈。这使得__cdecl支持可变数量的参数__fastcall: 一种尽可能通过寄存器而非堆栈传递参数的调用约定,可以提高函数的调用效率,特别是在参数数量较少时
因为 __stdcall 是由函数自己清理堆栈,所以需要明确知道堆栈上有多少字节需要被清理。所以 __stdcall 不支持可变数量参数。而 __cdecl 是调用者清理堆栈,所以根据传递给函数实际参数数量来调整堆栈指针
参数从左到右入栈的顺序不是在常见的 C/C++ 调用约定中看到的模式,因为在 C/C++ 中,无论是 __cdecl 还是 __stdcall 调用约定,参数都是从右到左入栈的。然而,在一些其他语言或特定的场景中,可能会看到从左到右的参数推入顺序。这些语言或平台可能设计了不同的调用约定来满足特定的需求或优化
使用 WINAPI 和 CALLBACK 宏的主要目的是确保函数与操作系统的互操作性,保持调用约定的一致性,从而使编译生成的代码能够正确地与操作系统交互。不正确的调用约定可能导致运行时错误,比如堆栈损坏,这会是难以调试的错误。通过标准化调用约定,Windows 确保了不同编译器和代码库之间的兼容性和稳定性
注册窗口
对于一个窗口程序来说,要做的事情有:窗口显示(窗口样式、行为等),在 Win32 程序中一般是先注册窗口类,再根据注册类创建窗口实例,实例就是真正控制的窗口
一个程序一般不止一个窗口
ATOM
WINAPI
RegisterClassExW(
_In_ CONST WNDCLASSEXW *);
#ifdef UNICODE
#define RegisterClassEx RegisterClassExW
#else
#define RegisterClassEx RegisterClassExA
#endif // !UNICODE
一般使用 RegisterClassEx 来注册类,它是 RegisterClass 函数的扩展
RegisterClass参数为WNDCLASS的结构指针RegisterClassEx参数为WNDCLASSEX的结构指针,该结构包括WNDCLASS的全部内容,并添加了额外字段:小图标(hIconSm)、任务栏图标等
typedef struct tagWNDCLASSEXA {
UINT cbSize;
UINT style;
WNDPROC lpfnWndProc;
int cbClsExtra;
int cbWndExtra;
HINSTANCE hInstance;
HICON hIcon;
HCURSOR hCursor;
HBRUSH hbrBackground;
LPCSTR lpszMenuName;
LPCSTR lpszClassName;
HICON hIconSm;
} WNDCLASSEXA, *PWNDCLASSEXA, *NPWNDCLASSEXA, *LPWNDCLASSEXA;
WNDCLASSEX 官方解释
官方文档对结构体成员属性有比较详细的解释,这里就不再搬运
需要注意的是 style 属性,我们使用的是 CS_OWNDC,也就是为类中的每个窗口分配唯一的设备上下文,也就是 Device Context 简称 DC,然后每个窗口就能被独立渲染。通常情况下,多个窗口可能会共享相同的设备上下文。如果一个窗口类被定义为 CS_OWNDC,则每个该类的窗口将获取一个独占的设备上下文,并保持这个设备上下文,直到窗口被销毁。这意味着窗口不需要在每次绘制时重新获取设备上下文,可以提高绘制效率
关于
style的官方解释
另一个需要注意的是 WNDPROC lpfnWndProc,指向窗口过程的指针。这个函数将处理所有有关这个窗口的信息,这些消息可以是用户的操作(如键盘输入、鼠标移动、点击等),或者是系统事件(如绘制消息、窗口大小改变等)。
typedef LRESULT (CALLBACK* WNDPROC)(HWND, UINT, WPARAM, LPARAM);
关于 WNDPROC 在官方文档有比较详细的解释
创建窗口
创建窗口一般使用 CreateWindowExA 函数
HWND CreateWindowExA(
[in] DWORD dwExStyle, // 窗口样式
[in, optional] LPCSTR lpClassName,
[in, optional] LPCSTR lpWindowName,
[in] DWORD dwStyle, // 窗口样式
[in] int X, // 窗口位置 X 坐标
[in] int Y, // 窗口位置 Y 坐标
[in] int nWidth, // 窗口宽度
[in] int nHeight, // 窗口高度
[in, optional] HWND hWndParent,
[in, optional] HMENU hMenu,
[in, optional] HINSTANCE hInstance,
[in, optional] LPVOID lpParam // 用与传递自定义数据
);
关于创建窗口,官方文档提供了比较详细的解释
创建窗口之后需要展示窗口, 也就是 ShowWindow
BOOL ShowWindow(
[in] HWND hWnd,
[in] int nCmdShow
);
关于显示窗口,官方文档有比较详细的解释
#include <Windows.h>
int WINAPI WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdSHow) {
const wchar_t* pClassName = L"hw3dbutts";
// 注册类
WNDCLASSEX wc = { 0 };
wc.cbSize = sizeof(wc);
wc.style = CS_OWNDC;
wc.lpfnWndProc = DefWindowProc;
wc.cbClsExtra = 0;
wc.cbWndExtra = 0;
wc.hInstance = hInstance;
wc.hIcon = nullptr;
wc.hCursor = nullptr;
wc.hbrBackground = nullptr;
wc.lpszMenuName = nullptr;
wc.lpszClassName = pClassName;
wc.hIconSm = nullptr;
RegisterClassEx(&wc);
// 创建窗口
HWND hWnd = CreateWindowEx(
WS_EX_RIGHTSCROLLBAR,
pClassName,
L"Hello World",
WS_SYSMENU | WS_CAPTION | WS_MAXIMIZEBOX,
200, 200, 640, 480,
nullptr, nullptr, hInstance, nullptr
);
// 展示窗口
ShowWindow(hWnd, SW_SHOW);
while (true)
{
}
return 0;
}
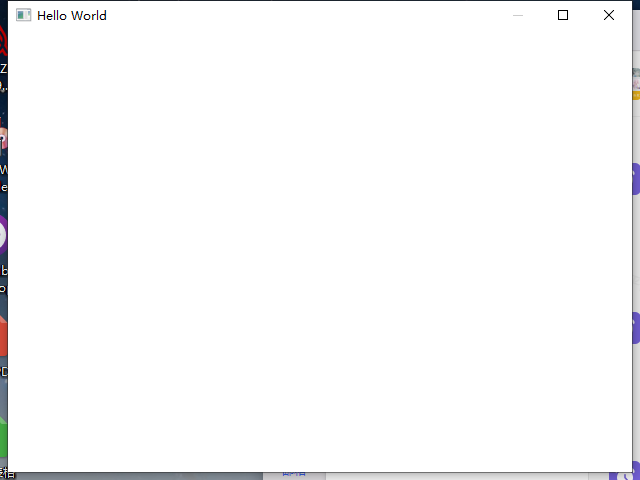
然后就可以得到一个不能做任何事情的窗口
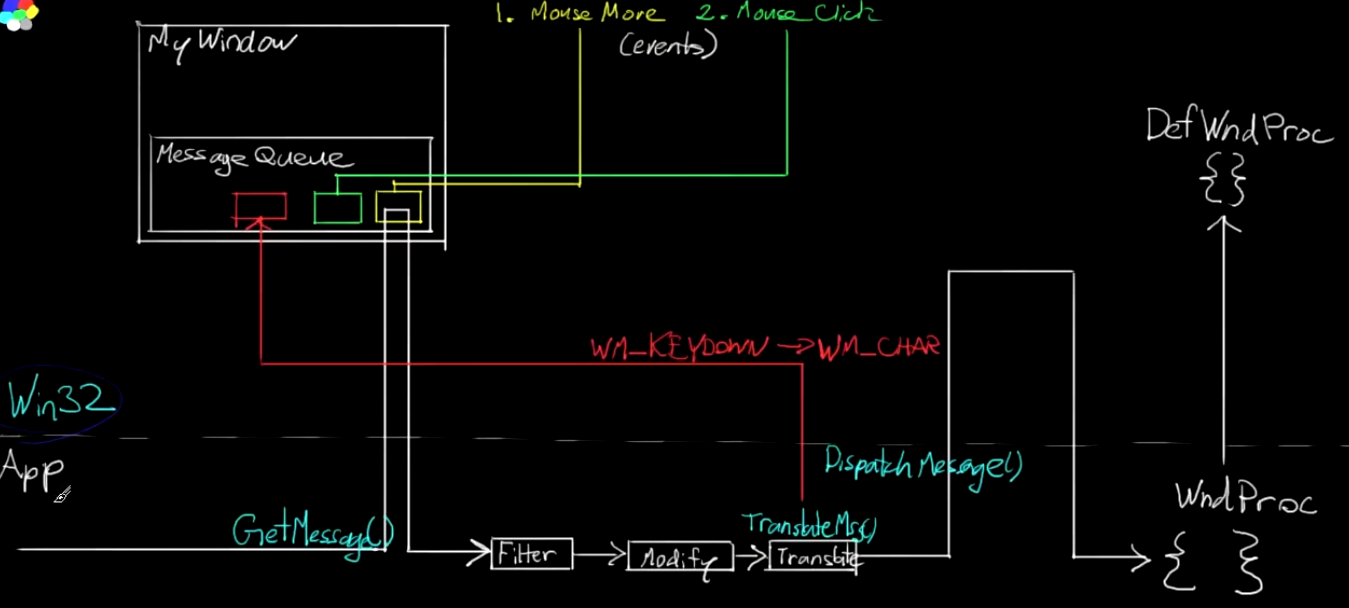
消息循环
对于窗口来说,除了窗口显示之外,还需要处理信息
比如 Visual Studio 需要处理键盘输入,我们要处理的窗口消息(Window Message) 本质上来说就是事件(Event)
当鼠标点击、鼠标移动、键盘输入等事件触发之后,窗口会首先把消息按顺序放进到消息队列(Message Queue) 中,可以通过 GetMessage 来获取队列中的消息,之后通过 DispatchMessage 把消息从应用传递给对应的窗口的 lpfnWndProc 函数
BOOL GetMessage(
[out] LPMSG lpMsg, // 消息的指针
[in, optional] HWND hWnd, // 处理信息的窗口指针
[in] UINT wMsgFilterMin,
[in] UINT wMsgFilterMax
);
wMsgFilterMin 和 wMsgFilterMax 用与过滤信息
如果 hWnd 为 NULL,GetMessage 将检索属于当前线程的任何窗口的消息
GetMessage 的值也同样需要注意,如果是退出窗口 WM_QUIT 则返回值为 0,否则是非零值。如果出现错误,则返回 -1
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) {
switch (msg)
{
case WM_CLOSE:
PostQuitMessage(69);
break;
default:
break;
}
return DefWindowProc(hWnd, msg, wParam, lParam);
}
// WinMain function
{
// Do Something
// 消息处理
MSG msg;
BOOL gResult;
while ((gResult = GetMessage(&msg, nullptr, 0, 0)) > 0)
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
if (gResult < 0) {
return -1; // 表示程序错误
}
return msg.wParam; // 否则输出我们期望的值 也就是 PostQuitMessage 传入的参数值
}
这里使用 WndProc 自定义的函数来接管默认的 DefWindowProc(Def 开头表示 Default),然后特殊处理 WM_CLOSE 时关闭程序,否则 DefWindowProc 只会关闭窗口而不会关闭进程
PostQuitMessage 函数将 WM_QUIT 消息发布到线程的消息队列并立即返回;函数只是向系统指示线程正在请求在将来的某个时间退出
当线程从其消息队列中检索 WM_QUIT 消息时,它应退出其消息循环,并将控制权返回到系统。 返回到系统的退出值必须是 WM_QUIT 消息的 wParam 参数
所以最后 WinMain 的输出是 msg.wParam,这样程序的代码是可以自定义的,未来可以通过这个结束码通知其他进程
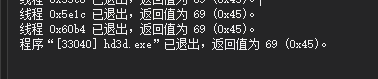
输出为 69 结果生效
这里使用 PostQuitMessage(69) 没有任何含义,单纯就是为了测试输出结果是否生效
窗口消息
消息的类型有很多
大概四百种类型,每种消息的触发条件可能需要自行测试
当然官网上也有一些消息类型的解释
除了官网和谷歌之外,还可以通过运行代码测试,何种情况触发何种宏来确定宏的触发条件
项目中使用 WIndowsMessageMap 来测试宏的触发,代码地址
以键盘按键为例

一次键盘的按下和松开会触发三个消息:WM_KEYDOWN、WM_CHAR 和 WM_KEYUP。当按下 D 键时,WM_KEYDOWN 的 wParam 输出为 0x0000044 ;当按下 F 键时,wParam 输出为 0x0000046,所以 wParam 可能存储了按下按钮相关信息
WM_CHAR 是用于文本输入的信息,所以一些按键按下之后不会触发 WM_CHAR,比如 F1、F2,并且 WM_CHAR 是大小写敏感的,WM_KEYDOWN 则大小写不敏感
同样按下 F 键,WM_KEYDOWN 的 wParam 是 0x0000046,表示大写的 F;而 WM_CHAR 的 wParam 是 0x0000066 表示小写的 f
case WM_CHAR:
{
static std::string title;
title.push_back((char)wParam);
SetWindowText(hWnd, to_wide_string(title).c_str());
break;
}

以鼠标点击为例

主要的消息触发就是:WM_LBUTTONDOWN 和 WM_LBUTOTNUP 来表示鼠标左键的点击和松开,对应的鼠标右键点击就是 WM_RBUTTONDOWN 和 WM_RBUTTONUP,鼠标移动有 WM_MOUSEMOVE
LBUTTONDOWN 更多参数信息官方文档有说明
POINT pt;
pt.x = GET_X_LPARAM(lParam);
pt.y = GET_Y_LPARAM(lParam);
pt = MAKEPOINTS(lParam);
通过上面俩种方法可以获得鼠标相对工作区左上角的坐标
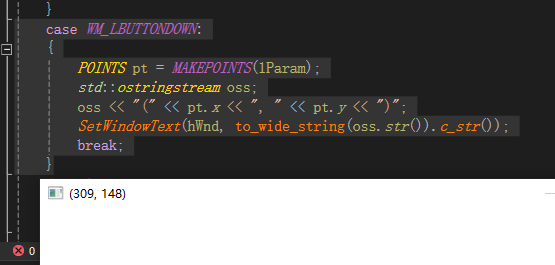
case WM_LBUTTONDOWN:
{
POINTS pt = MAKEPOINTS(lParam);
std::ostringstream oss;
oss << "(" << pt.x << ", " << pt.y << ")";
SetWindowText(hWnd, to_wide_string(oss.str()).c_str());
break;
}
封装Window
由于该项目只有一个窗口,所以直接做成一个单例类
class Window
{
private:
// singleton manages registration/cleanup of window class
class WindowClass;
private:
static LRESULT CALLBACK HandleMsgSetup(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) noexcept;
static LRESULT CALLBACK HandleMsgThunk(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) noexcept;
LRESULT HandleMsg(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) noexcept;
}
WindowClass 是窗口的实例类,由 Window 来管理
WindowClass 是单例类,所以会在获取 GetInstance 时构建和注册一个窗口
Window::WindowClass::WindowClass() noexcept : hInst(GetModuleHandle(nullptr))
{
WNDCLASSEX wc = { 0 };
wc.cbSize = sizeof(wc);
wc.style = CS_OWNDC;
wc.lpfnWndProc = HandleMsgSetup;
// ... 其他注册内容
RegisterClassEx(&wc);
}
在 Window 类创建的时候会通过 WindowClass 构建和注册一个窗口,再由 Window 来创建出窗口
Window::Window(int InWidth, int InHeight, const wchar_t* InName) noexcept
{
RECT Wr;
Wr.left = 100;
Wr.right = InWidth + Wr.left;
Wr.top = 100;
Wr.bottom = InHeight + 100;
// AdjustWindowRect 会根据样式重新计算 RECT 中各个参数的值
AdjustWindowRect(&Wr, WS_CAPTION | WS_MINIMIZEBOX | WS_SYSMENU, FALSE);
// 重新设置过 RECT 参数,所以这里不能直接使用 InWidth 和 InHeight
hWnd = CreateWindow(
WindowClass::GetName(), InName,
WS_CAPTION | WS_MINIMIZEBOX | WS_SYSMENU,
CW_USEDEFAULT, CW_USEDEFAULT, Wr.right - Wr.left, Wr.bottom - Wr.top,
nullptr, nullptr, WindowClass::GetInstance(), this
);
ShowWindow(hWnd, SW_SHOWDEFAULT);
}
这里需要注意的是 wc.lpfnWndProc = HandleMsgSetup 绑定的窗口信息函数
LRESULT Window::HandleMsgSetup(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) noexcept
{
if (msg == WM_NCCREATE)
{
const CREATESTRUCTW* const pCreate = reinterpret_cast<CREATESTRUCTW*>(lParam);
Window* const pWnd = static_cast<Window*>(pCreate->lpCreateParams);
SetWindowLongPtr(hWnd, GWLP_USERDATA, reinterpret_cast<LONG_PTR>(pWnd));
SetWindowLongPtr(hWnd, GWLP_WNDPROC, reinterpret_cast<LONG_PTR>(&Window::HandleMsgThunk));
return pWnd->HandleMsg(hWnd, msg, wParam, lParam);
}
return DefWindowProc(hWnd, msg, wParam, lParam);
}
当 WM_NCCREATE 被触发的时候,重新设置 GWLP_USERDATA 和 GWLP_WNDPROC,也就将消息的回调函数设置成了 Window::HandleMsgThunk
为什么要切换信息回调函数呢?
- 组织性:
HandleMsgSetup专注于窗口创建时的设置工作,而HandleMsgThunk用于处理窗口的常规消息。这种分离使得代码更加清晰和易于管理 - 安全性:在窗口创建期间,可能会收到各种消息,但在窗口类与窗口句柄关联之前,这些消息不应该被传递到窗口类的实例。
HandleMsgSetup确保只有在关联建立之后,消息才会被转发到窗口类的实例 - 效率:一旦窗口创建完成并且关联建立,
HandleMsgThunk将直接转发消息到窗口类的实例,无需每次都检查WM_NCCREATE消息。这提高了消息处理的效率 - 灵活性:如果将来需要在窗口创建过程中添加更多的初始化代码,只需修改
HandleMsgSetup函数即可,而不会影响到常规消息处理的代码
这里不得不提到 WM_NCCREATE ,这个宏的 NCCREATE 可以拆分成 NC 和 CREATE,后者 CREATE 就是创建的意思;前者 NC 表示的是 No-Client

以上图为例,图中标题栏的边框,最大化最小化按钮,以及其他UI元素,这个边框称为 Window的 no-client 区域。
WM_NCCREATE 在 WM_CREATE 之前发送
在这之前的消息都会被 HandleMsgSetup 吃掉,因为客户端一般不用处理这之前的消息
通过 SetWindowLongPtr 就设定了 GWLP_USERDATA 用户自定义数据中存储的 Window 对象指针
LRESULT Window::HandleMsgThunk(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) noexcept
{
Window* const pWnd = reinterpret_cast<Window*>(GetWindowLongPtr(hWnd, GWLP_USERDATA));
return pWnd->HandleMsg(hWnd, msg, wParam, lParam);
}
在 HandleMsgThunk 函数中,通过 GetWindowLongPtr 的方式将 Window 对象的指针从 GWLP_USERDATA 中取出,并将消息转发到 HandleMsg 中
由于 WINAPI 回调函数需要符合特定的签名,并且必须能够通过全局访问,因此它们不能直接绑定到类的非静态成员函数,这个函数必须是一个全局函数或静态成员函数
所以通过上面的方法,将全局事件分发到成员函数 Window::HandleMsg 中
异常处理
// 异常基类
class ChiliException: public std::exception
{
public:
ChiliException(int line, const char* file) noexcept;
const char* what() const noexcept override;
virtual const char* GetType() const noexcept;
int GetLine() const noexcept;
const std::string& GetFile() const noexcept;
std::string GetOriginString() const noexcept;
private:
int line; // 错误出现的行
std::string file; // 错误出现的文件
protected:
mutable std::string whatBuffer;
};
// Window 异常类
class Exception : public ChiliException {
public:
Exception(int line, const char* file, HRESULT InHr);
const char* what() const noexcept override;
virtual const char* GetType() const noexcept;
static std::string TranslateErrorCode(HRESULT InHr);
HRESULT GetErrorCode() const noexcept;
std::string GetErrorString() const noexcept;
private:
HRESULT hr;
};
#define CHWND_EXCEPT(hr) Window::Exception(__LINE__, __FILE__, hr)
所以的异常都基于 ChiliException 扩展即可,重写 GetType 和 what 函数,即可将错误分类
那么,在日常使用的时候,如果 Window 需要抛出异常,直接使用 CHWND_EXCEPT 即可
常见的 system error code 在 官方文档 中有比较详细的介绍

throw CHWND_EXCEPT(ERROR_ARENA_TRASHED)
D3D
架构/交换链
架构
D3D: DirectX 3D
D3D 是面向对象对象的架构,建立在 COM(Component Object Moduel, 组件对象模型) 对象上,这些对象表示着 D3D 中的实体(例如:着色器、纹理、状态等),这些物体的父类都是 Device
COM 是 D3D 中使用的软件架构,旨在突进软件组件之间的交互。COM 是一个面向接口的系统,它定义了对象如何通过一组明确的接口与外部世界通信。所有 COM 对象都继承自 IUnknow 接口,这是 COM 规范中的基础接口,提供了对象生命周期管理(引用计数)和接口查询功能
在 Direct3D 中,几乎所有的对象(如设备、纹理、缓冲区等)都是以 COM 接口的形式实现的。这些对象实现 COM 接口,确保了它们可以在多种编程环境中以一致的方式使用,并且能够在不同版本的 Direct3D 间提供一定程度的向后兼容性
- 接口查询(
Query Interface):每个 COM 对象都可以通过QueryInterface来查询是否支持特定的接口,这运行开发者根据运行时可以同的功能动态访问不同的接口 - 引用计数:通过
AddRef和Release来增减引用计数 - 版本控制和兼容性,在不破坏现有程序的情况下引入新的接口和功能
Device 在 Direct3D 中扮演中心角色,是进行所有渲染操作和资源管理的核心接口。它是由 Direct3D 创建并返回给应用程序的一个 COM 接口,允许应用程序通过调用此接口的方法来执行图形和计算任务
- 纹理:通过
ID3D11Device::CreateTexture2D等方法创建 - 着色器:通过
ID3D11Device::CreateVertexShader、ID3D11Device::CreatePixelShader等方法创建 - 状态对象:如通过
ID3D11Device::CreateBlendState、ID3D11Device::CreateRasterizerState等方法创建
在 Direct3D 中,Device 和其他资源如着色器、纹理、状态等之间的关系可以总结如下:
- 创建者与被创建者:
Device是创建和管理所有其他图形资源的中心。所有这些资源(着色器、纹理、状态等)都由Device接口创建 - COM 对象:
Device以及它创建的所有其他资源都是COM对象,遵守COM接口和引用计数的规则 - 接口和实现解耦:作为
COM对象,Device和其他资源的实现被抽象和封装,开发者主要通过接口与这些资源交互。这允许 Direct3D 在不影响已有应用的情况下进行更新和改进
交换链
如果显存中只存在一块区域用与显示,每次显卡都会将这块区域的数据发送到显示器中绘制。当我们更新数据时,可能只绘制了一部分就被显卡发送到显示进行绘制了,这样会出现屏幕的撕裂
所以一般使用俩块缓冲区,一块专门用于提供给显示器进行渲染,称为前缓冲区;一块专门用于实际绘制,称为后缓冲区
当后缓冲区绘制完毕之后,会使用 Present 的方法,将后缓冲区非常快的复制到前缓冲上;或者使用 Flip 的方法,直接将后缓冲重命名为前缓冲,前缓冲重命名为后缓冲
这里必须提到 DXGI(DirectX Graphics Infrastructure) 是一个低级的 API,用于抽象和管理图形硬件资源。它是 DirectX 家族的一部分,主要负责处理图形设备的枚举、显示监控的管理、交换链(用于图像呈现的缓冲区管理)以及帧的呈现
DXGI 为 DirectX 提供核心功能,特别是与显示设备和屏幕缓冲区的交互
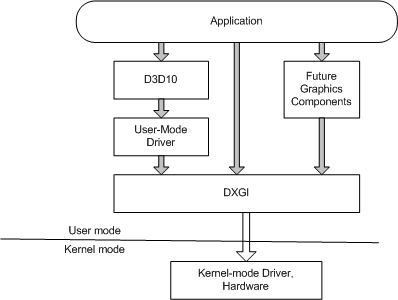
DXGI 的目的是与内核模式驱动程序和系统硬件通信
应用程序可以直接访问 DXGI,也可以调用 Direct3D API,以处理与 DXGI 的通信。 如果应用程序需要枚举设备或控制如何将数据呈现给输出,则可能需要直接使用 DXGI
上下文
D3D 除了创建交换链、设备外还会创建上下文(Context),用于发出渲染你命令平配置渲染管道
一般来说 设备(Device) 用于创建物体,上下文(Context) 用于绘制
上下文分为即时和延迟俩种,当调用即时上下文时,会让硬件马上执行渲染工作;延迟上下文会建立指令集,然后将指令发布到即时上下文中,所以延迟上下文在多线程中表现良好
命令队列、命令列表、命令分配器
图形编程时,CPU 和 GPU 都在参与处理工作,为了获得最佳性能,最好的情况就是让两者尽量同时工作

命令队列是一个接口,用于管理和调度待执行的命令列表。它负责接收提交的命令列表,并按照特定的顺序(如先入先出)将命令发送到 GPU 执行。命令队列可以是不同类型的,例如直接命令队列(用于大部分渲染和复制操作)、复制命令队列(专门用于复制操作)、计算命令队列(专门用于计算任务)
当一系列命令被提交到命令队列时,并不会被 GPU 立即执行,GPU 可能正在处理先前插入的命令
命令分配器是用于命令列表的内存管理。每个命令列表在记录命令之前都需要绑定一个命令分配器。命令分配器负责分配存储命令的内存空间。当命令列表被执行完毕后,可以重置命令分配器以回收内存资源,供未来的命令列表重用。重要的是,命令分配器在重置时必须确保没有任何与之相关的命令列表正在 GPU 上执行
命令列表是记录所有渲染和计算命令的接口。开发人员使用命令列表来设置渲染状态、绑定资源和调度渲染命令等。命令列表在使用前需要与一个命令分配器关联,以获得所需的内存资源。完成命令的记录后,命令列表会被提交给命令队列进行执行
- 命令分配器和命令列表:每个命令列表在创建时都需要指定一个命令分配器。命令分配器为命令列表提供所需的内存资源。一个命令分配器可以与多个命令列表关联,但在任意时刻只能有一个命令列表与之关联。当命令列表执行完毕并且命令队列不再引用该命令列表时,可以重置命令分配器以供其他命令列表使用
- 命令队列和命令列表:命令列表记录完毕后,通过命令队列提交给 GPU 执行。命令队列负责安排这些命令的执行顺序,并确保它们被正确处理
这种设计允许高度的并行和效率,因为可以同时记录多个命令列表,而这些命令列表又可以在不同的线程中被创建和管理。此外,通过独立控制命令的记录和执行,DirectX 12 能够提供比以往更精细的控制和更优的性能
Fence 围栏

模型资源 R
- CPU 一开始设置了 R 的位置信息 P1
- 添加命令 C 给 GPU 绘制模型 R
- CPU 继续计算,重新设置模型 R 的位置信息 P2
在进行到第三步的时候,如果 GPU 此时并没有执行完命令 C (可能还没执行,也可能在执行中),所以模型的坐标不会被绘制到 P1 上,这与期待的命令不合
这种情况的一种解决方案是强制 CPU 等待,知道 GPU 完成所有的命令处理,达到某个指定的围栏点(Fence Point)
这种方法称为刷新命令队列,可以通过围栏(Fence) 来实现
HRESULT CreateFence(
UINT64 InitialValue, // 围栏的初始值
D3D12_FENCE_FLAGS Flags,
REFIID riid,
[out] void **ppFence
);
围栏对象维护着一个 UINT64 类型的值,这是用来表示围栏点的整数,每当需要标记新的围栏点时就将其加1
这样做并不完美,因为在等待 GPU 执行命令时 CPU 会进入空闲状态
资源、描述符、描述符堆
通过 D3D12_DESCRIPTOR_HEAP_DESC 堆描述结构体,来描述一个堆,然后通过 device 来创建这个描述符堆,例如:rtvHeapDesc 和 dsvHeapDesc
常用的描述符有:
CBV(constant buffer view):常量缓冲区视图SRV(shader resource view):着色器资源视图UAV(unorder access view):无序访问视图Sampler:采样器,用于采样纹理资源RTV(render target view):渲染目标视图DSV(depth/stencil view):深度/模板视图
描述符:是对资源的引用,存储在描述符堆中,用于高效的 GPU 访问
视图:是资源的具体解释,定义了资源的使用方式(如读取、写入等),实际上通过描述符来创建
描述符堆(Descriptor Heap)是一种关键的资源管理工具,用于存储和组织资源描述符。资源描述符是指向资源(如纹理、缓冲区、采样器等)的句柄或指针,它提供了 GPU 所需的足够信息来访问这些资源
描述符堆实际上就是存放描述符的数组,本质上是存放特定类型描述符的一块内存
关于D3D12_DESCRIPTOR_HEAP_DESC的各个属性文档中有比较的说明
描述符堆具体是存储什么描述符是通过 D3D12_DESCRIPTOR_HEAP_DESC 的 Type 属性来决定的
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV: 可以存放CBV, SRV和UAVD3D12_DESCRIPTOR_HEAP_TYPE_SAMPLER: 存放samplerD3D12_DESCRIPTOR_HEAP_TYPE_RTV: 存放RTVD3D12_DESCRIPTOR_HEAP_TYPE_DSV: 存放DSV
描述符堆的 Flag 属性用来指定描述符堆的可见性,即可以被哪些管线阶段访问
D3D12_DESCRIPTOR_HEAP_FLAG_NONE: 创建只由 CPU 访问的描述符堆,例如专门用于渲染目标视图(RTV)或深度模板视图(DSV)的描述符堆D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE: 述符堆可以被着色器程序直接访问
RTVs 和 DSVs 在常规渲染流程中不需要由着色器直接访问,因为它们通常是由输出合并阶段使用
在发出绘制命令之前,需要将本次绘制调用(draw call)相关的资源绑定(bind或link)到资源流水线上。部分资源可能在每次绘制调用时都会有所变化,所以每次按需更新绑定
GPU 资源并非直接与流水线相绑定,而是通过描述符对象来间接引用,通过描述符 GPU 既能获取实际的资源数据,也能了解到资源的必要信息,即资源格式和如何使用
使用描述符来表示资源是因为 GPU 资源实际上都是一些普通的内存块,很多时候只希望将部分数据绑定到渲染流水线,那么从整个资源中将其选出?或者内存块如何使用?这些都是记录在描述符中的
- 应用程序使用
RTVHeap来存储RTV描述符 - 每个
RTV描述符都指向SwapChainBuffer中的一个缓冲区 SwapChain管理这些缓冲区,并在适当的时候将它们呈现到屏幕上
资源转换
为了实现常见的渲染效果,经常会通过 GPU 对某个资源 R 按顺序进行先写后读两种操作
当 GPU 的写操作还没完成或者甚至没开始的时候,却开始读取资源,便会导致资源冒险
Direct3D 专门针对资源提供了一组相关状态,资源最开始处于默认状态,该状态会一直持续到应用程序通过 Direct3D 将其转换(transition)为另一中状态为止
比如如果要对某个纹理资源执行写操作,需要先将其设置为渲染目标状态;如果对纹理进行读操作,需要将其转换为着色器资源状态
通过命令列表设置转换资源屏障数组,即可执行资源的转换
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mDepthStencilBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_DEPTH_WRITE));
资源驻留
对于复杂场景,一些资源并不需要一开始就加载在显存中
一般来说,资源在创建时就会驻留在现存中,而当被销毁时清出。但是 DirectX 提供两种方法来主动控制资源的驻留
HRESULT ID3D12Device::MakeResident
HRESULT ID3D12Device::Evict
初始化项目
封装报错宏
#ifndef ThrowIfFailed
#define ThrowIfFailed(x) \
{ \
HRESULT hr__ = (x); \
std::wstring wfn = AnsiToWString(__FILE__); \
if(FAILED(hr__)) { throw DxException(hr__, L#x, wfn, __LINE__); } \
}
#endif
需要初始化窗口和 D3D 程序
初始化窗口其实就是前面封装的 Window,而 DX12 中初始化 D3D 需要依次创建
DXGI工厂,用于创建设备和交换链,以及查询显卡(适配器)信息
// 创建 DXGI 工厂
ThrowIfFailed(CreateDXGIFactory1(IID_PPV_ARGS(&mdxgiFactory)));
Device设备,图形驱动程序的接口。它用于创建所有的D3D资源,如纹理、缓冲区和命令列表
// 创建硬件 Device
HRESULT hardwareResult = D3D12CreateDevice(
nullptr, // nullptr 表示默认显卡适配器
D3D_FEATURE_LEVEL_11_0,
IID_PPV_ARGS(&md3dDevice));
// 如果硬件 Device 无法创建
if(FAILED(hardwareResult))
{
// 通过 EnumWarpAdapter 获取 WARP 软件光栅器
ComPtr<IDXGIAdapter> pWarpAdapter;
ThrowIfFailed(mdxgiFactory->EnumWarpAdapter(IID_PPV_ARGS(&pWarpAdapter)));
ThrowIfFailed(D3D12CreateDevice(pWarpAdapter.Get(), D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&md3dDevice)));
}
WARP(Windows Advanced Rasterization Platform),高性能的软件光栅器
Command Queue,命令队列,用于与设备通信的接口,用于提交执行命令列表,GPU 执行命令的调度基础
void D3DApp::CreateCommandObjects()
{
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&mCommandQueue)));
ThrowIfFailed(md3dDevice->CreateCommandAllocator(
D3D12_COMMAND_LIST_TYPE_DIRECT,
IID_PPV_ARGS(mDirectCmdListAlloc.GetAddressOf())));
ThrowIfFailed(md3dDevice->CreateCommandList(
0, // 0 表示节点掩码,用于单 GPU 系统
D3D12_COMMAND_LIST_TYPE_DIRECT,
mDirectCmdListAlloc.Get(), // Associated command allocator
nullptr, // 表示初始状态下没有绑定任何管线状态对象(PSO)
IID_PPV_ARGS(mCommandList.GetAddressOf())));
// 创建后,默认命令列表是开放状态,可以记录命令。调用 Close 方法将其关闭,这是提交之前的必要步骤
mCommandList->Close();
}
Swap Chain交换链,用于管理渲染数据缓冲区
void D3DApp::CreateSwapChain()
{
// Release the previous swapchain we will be recreating.
mSwapChain.Reset();
DXGI_SWAP_CHAIN_DESC sd;
sd.BufferDesc.Width = mClientWidth; // 缓冲区分辨率的宽度
sd.BufferDesc.Height = mClientHeight; // 缓冲区分辨率的高度
sd.BufferDesc.RefreshRate.Numerator = 60; // 刷新率
sd.BufferDesc.RefreshRate.Denominator = 1;
sd.BufferDesc.Format = mBackBufferFormat; // 缓冲区的显示格式
sd.BufferDesc.ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED; // 逐行扫描 / 隔行扫描
sd.BufferDesc.Scaling = DXGI_MODE_SCALING_UNSPECIFIED; // 图像如何对屏幕进行拉伸
sd.SampleDesc.Count = m4xMsaaState ? 4 : 1; // 每个像素的多样本数
sd.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0; // 图像质量级别。 质量越高,性能越低
sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT; //
sd.BufferCount = SwapChainBufferCount; // 交换链中所用的缓冲区数量
sd.OutputWindow = mhMainWnd; // 渲染窗口的句柄
sd.Windowed = true; // true 窗口模式 / false 全屏模式
sd.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD; // 设置交换效果,这里使用 `DXGI_SWAP_EFFECT_FLIP_DISCARD`,这意味着使用翻转模型并且在显示后丢弃旧内容,这种方式可以提高性能并减少延迟
sd.Flags = DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH; //
// 使用 DXGI 工厂对象 (mdxgiFactory) 创建交换链,传入先前配置的描述符 sd 和使用的命令队列(mCommandQueue)
ThrowIfFailed(mdxgiFactory->CreateSwapChain(
mCommandQueue.Get(),
&sd,
mSwapChain.GetAddressOf()));
}
Descriptor Heaps描述符堆,用于春初资源描述符的几何Command Alloctor命令分配器,每个命令列表需要一个命令分配器用于管理内存Command List命令列表,用于记录所以的渲染命令Fence用于 CPU 和 GPU 之间的同步
ThrowIfFailed(md3dDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&mFence)));
围栏是一种同步机制,用于协调 CPU 和 GPU 之间的操作顺序。通过围栏,开发者可以控制资源的使用时机,确保在资源被 GPU 更新或读取前,CPU 上的操作已经完成,从而避免竞态条件和数据损坏
- 资源和视图
以 RTV(Render Target View,渲染目标视图) 和 DSV(Depth Stencil View,深度模板视图) 为例
void D3DApp::CreateRtvAndDsvDescriptorHeaps()
{
D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc;
rtvHeapDesc.NumDescriptors = SwapChainBufferCount;
rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
rtvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(
&rtvHeapDesc, IID_PPV_ARGS(mRtvHeap.GetAddressOf())));
D3D12_DESCRIPTOR_HEAP_DESC dsvHeapDesc;
dsvHeapDesc.NumDescriptors = 1;
dsvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_DSV;
dsvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
dsvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(
&dsvHeapDesc, IID_PPV_ARGS(mDsvHeap.GetAddressOf())));
}
由于不同平台描述符大小不同,所以通过特定接口获得描述符大小,并存储下来供未来使用
mRtvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
mDsvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_DSV);
mCbvSrvUavDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
Resize
在所有数据都初始化完毕之后,就可以根据窗口大小和视口大小来设置数据
由于这些操作在屏幕大小更改之后也要进行,所以直接一起封装到 OnResize 函数中
- 检查关键对象存在,并清空命令队列
assert(md3dDevice);
assert(mSwapChain);
assert(mDirectCmdListAlloc);
// Flush before changing any resources.
FlushCommandQueue();
- 重置命令列表
ThrowIfFailed(mCommandList->Reset(mDirectCmdListAlloc.Get(), nullptr));
- 释放旧资源
释放所有交换链缓冲区和深度模板缓冲区的引用,准备重新创建它们
for (int i = 0; i < SwapChainBufferCount; ++i)
mSwapChainBuffer[i].Reset();
mDepthStencilBuffer.Reset();
- 调整交换链大小
使用新的窗口 dimensions 调整交换链缓冲区的大小。mClientWidth 和 mClientHeight 为新的尺寸
ThrowIfFailed(mSwapChain->ResizeBuffers(SwapChainBufferCount, mClientWidth, mClientHeight, mBackBufferFormat, DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH));
- 重新创建和绑定 RTV
重新获取每个交换链缓冲区的引用,并为每个缓冲区创建新的 RTV
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(mRtvHeap->GetCPUDescriptorHandleForHeapStart());
for (UINT i = 0; i < SwapChainBufferCount; i++)
{
ThrowIfFailed(mSwapChain->GetBuffer(i, IID_PPV_ARGS(&mSwapChainBuffer[i])));
md3dDevice->CreateRenderTargetView(mSwapChainBuffer[i].Get(), nullptr, rtvHeapHandle);
rtvHeapHandle.Offset(1, mRtvDescriptorSize);
}
- 创建新的深度/模板缓冲区
配置并创建新的深度/模板缓冲区以匹配新的窗口尺寸
设置资源的类型、宽度、高度和格式等属性
创建深度模板视图 (DSV)
// Various settings for the depth/stencil buffer are defined here.
D3D12_RESOURCE_DESC depthStencilDesc;
...
ThrowIfFailed(md3dDevice->CreateCommittedResource(...));
D3D12_DEPTH_STENCIL_VIEW_DESC dsvDesc;
...
md3dDevice->CreateDepthStencilView(mDepthStencilBuffer.Get(), &dsvDesc, DepthStencilView());
- 设置资源状态和执行命令
之前创建的深度模板视图是一个 Texture2D 的资源,资源需要设置状态才能给对应部分使用,所以使用 CD3DX12_RESOURCE_BARRIER::Transition 设置资源状态
// Transition the resource from its initial state to be used as a depth buffer.
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mDepthStencilBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_DEPTH_WRITE));
// Execute the resize commands.
ThrowIfFailed(mCommandList->Close());
ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
- 等待命令执行完毕,更新视口大小
// Wait until resize is complete.
FlushCommandQueue();
// Update the viewport transform to cover the client area.
mScreenViewport.TopLeftX = 0;
mScreenViewport.TopLeftY = 0;
mScreenViewport.Width = static_cast<float>(mClientWidth);
mScreenViewport.Height = static_cast<float>(mClientHeight);
mScreenViewport.MinDepth = 0.0f;
mScreenViewport.MaxDepth = 1.0f;
mScissorRect = { 0, 0, mClientWidth, mClientHeight };
Draw
通过 OnResize 创建/更新了所有数据,然后通过 Draw 就可以根据已有数据进行绘制
void InitDirect3DApp::Draw(const GameTimer& gt)
{
// 重置命令分配器和命令列表
ThrowIfFailed(mDirectCmdListAlloc->Reset());
ThrowIfFailed(mCommandList->Reset(mDirectCmdListAlloc.Get(), nullptr));
// 设置资源状态转换
// 这行代码指示 GPU 将当前后台缓冲区的状态从 PRESENT(表示缓冲区已准备好显示)转换为 RENDER_TARGET(表示缓冲区准备接受渲染命令)
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(),
D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET));
// 设置视口和剪裁矩形
mCommandList->RSSetViewports(1, &mScreenViewport);
mCommandList->RSSetScissorRects(1, &mScissorRect);
// 清除后台缓冲区和深度缓冲区
// 使用 Colors::LightSteelBlue 来填充后台缓冲区颜色
mCommandList->ClearRenderTargetView(CurrentBackBufferView(), Colors::LightSteelBlue, 0, nullptr);
mCommandList->ClearDepthStencilView(DepthStencilView(), D3D12_CLEAR_FLAG_DEPTH | D3D12_CLEAR_FLAG_STENCIL, 1.0f, 0, 0, nullptr);
// 指定 GPU 在渲染过程中使用的渲染目标(后台缓冲区)和深度模板视图
mCommandList->OMSetRenderTargets(1, &CurrentBackBufferView(), true, &DepthStencilView());
// 在渲染命令完成后,将后台缓冲区的状态从 RENDER_TARGET 转换回 PRESENT,准备显示
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(),
D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT));
// 提交命令列表,执行和呈现
ThrowIfFailed(mCommandList->Close());
ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
ThrowIfFailed(mSwapChain->Present(0, 0));
mCurrBackBuffer = (mCurrBackBuffer + 1) % SwapChainBufferCount;
// 后台缓冲区序号更新和命令队列清空
FlushCommandQueue();
}
mCurrBackBuffer = (mCurrBackBuffer + 1) % SwapChainBufferCount 用于获取当前能够使用的后台缓冲区,当前缓冲区正在使用,所以下一帧只能用另一个,避免使用同一个缓冲区
基本运行框架
基本按照之前的 Windows 窗口程序来运行
如果存在消息,则优先处理窗口信息;如果信息都处理完了,则开始更新数据和绘制画面
如果 mAppPaused,一般是处在后台,那么直接粗暴的 Sleep
int D3DApp::Run()
{
MSG msg = {0};
mTimer.Reset();
while(msg.message != WM_QUIT)
{
// If there are Window messages then process them.
if(PeekMessage( &msg, 0, 0, 0, PM_REMOVE ))
{
TranslateMessage( &msg );
DispatchMessage( &msg );
}
// Otherwise, do animation/game stuff.
else
{
mTimer.Tick();
if( !mAppPaused )
{
CalculateFrameStats();
Update(mTimer);
Draw(mTimer);
}
else
{
Sleep(100);
}
}
}
return (int)msg.wParam;
}
渲染流水线

输入装配器阶段
输入装配器(Input Assembler, IA) 阶段会从现存中读取几何数据(顶点和索引, Vertex And Index),再将他们装配为几何图元(geometric primitive,如三角形和线条这种构成图形的基本元素)
在 Direct3D 中通过 Vertex Buffer 的特殊数据结构将顶点与渲染流水线绑定
Vertext Buffer 利用连续的内存来存储一系列顶点
除了顶点之外,还需要指定图元拓扑(primitive topology)来告知如何用顶点数据来表示几何图元
mCommandList->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
上述代码就是在设置图元拓扑类型,枚举类型为: D3D_PRIMITIVE_TOPOLOGY,枚举值有点多,在官方文档中有详细说明
D3D_PRIMITIVE_TOPOLOGY_POINTLIST, // 将顶点数据解释为点列表
D3D_PRIMITIVE_TOPOLOGY_LINELIST, // 将顶点数据解释为线条列表
D3D_PRIMITIVE_TOPOLOGY_LINESTRIP, // 将顶点数据解释为线条带
D3D_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP, // 将顶点数据解释为三角形带
// ....
| 点列表 | 线条列表 | 线条带 | 三角形条带 |
|---|---|---|---|
 |
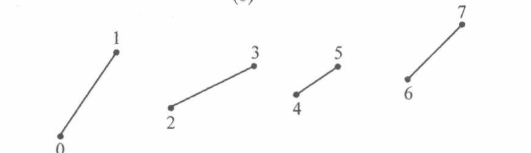 |
 |
 |
可以通过顶点坐标构成各种图形,但是有一个问题,那就是数据冗余的问题,以下图纹理
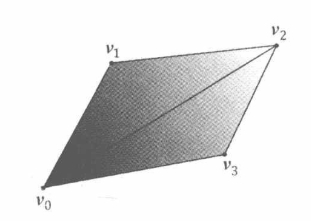
Vertex quad[6] = {
v0, v1, v2, // 三角形1
v0, v2, v3, // 三角形2
}
通过 quad 数组可以获得俩个三角形拼成的四边形,但是两个三角形中有两个数据(v0, v2)冗余了
顶点中除了坐标信息,还可以存储颜色、法线等信息,这就意味着内存的浪费,为了处理这个冗余的问题,于是采用索引的方式来记录图元的顶点信息
Vertex v[4] = {v0, v1, v2, v3};
UINT indexList[6] = {
0, 1, 2, // 三角形1
0, 2, 3, // 三角形2
}
让图元的顶点信息通过索引获得, 这样顶点信息就没有冗余
顶点着色器阶段
图元装配完毕之后,其顶点就会被送入顶点着色器阶段
可以把顶点主送二七看作一种输入与输出皆为单个顶点的函数。每个要被绘制的顶点都须经过顶点着色器的处理,再送往后续阶段
for(UINT i = 0; i < numVertices; ++i) {
outputVertex[i] = VertexShader(inputVertex[i]);
}
顶点着色器函数就是
VertexShader要实现的部分
通过顶点着色器可以实现变换、光照、位移贴图等特效。顶点着色器也可以访问顶点数据、纹理和其他存于显存中的数据(如变换矩阵、光照信息等)
曲面细分阶段
曲面细分阶段利用镶嵌化处理技术对网格中的三角形进行细分,以此来增加物体表面上的三角形数量。再将新增的三角形偏移到适当的位置,是网格表现出更加细腻的细节
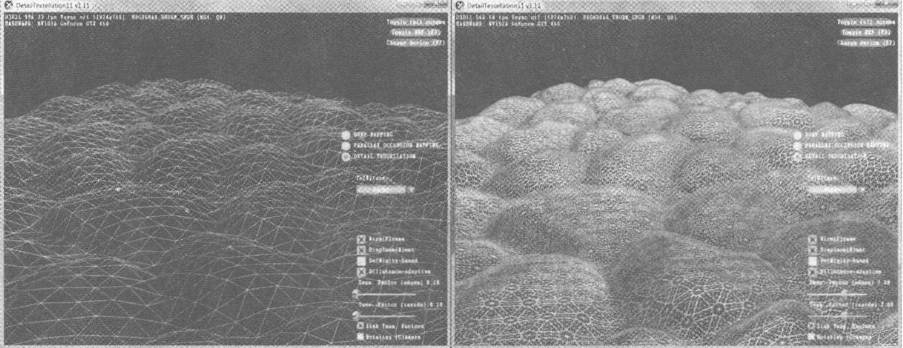
- 可以实现细节层次机制(
Level-of-Detail,LOG),即离虚拟相机近的三角形镶嵌化处理得到更丰富的细节,离相机远的三角形不进行任何更改 - 内存中只需要维护简单的低模网格,再根据需要动态增添额外三角形面
- 处理动画和物理模拟时采用简单的低模网格,仅在渲染的过程中使用经镶嵌化处理的高模网格
几何着色器
几何着色器接受的输入应该是完整的图元,例如正在绘制三角形列表,那么几何着色器传入的将是定义三角形的三个顶点
几何着色器可以创建或者销毁几何体,可以利用几何着色器将输入的图元拓展为一个或者多个其他图元
裁剪
位于视锥体之外的几何体需要被丢弃,而处于平截头体交界意外的几何部分也一定要接受被裁剪的操作。因此只有在平截头体之内的物体对象才能最终保留下来
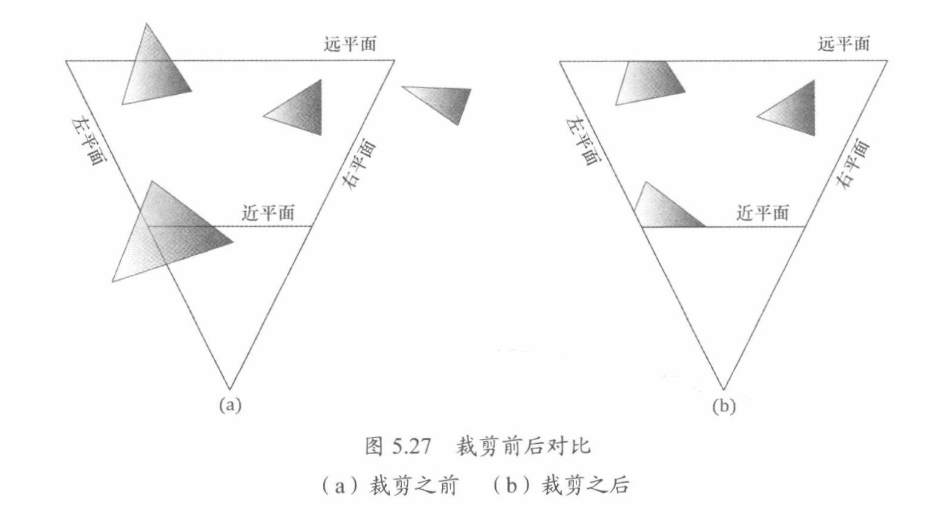
顶视图
光栅化
光栅化阶段(rasterization stage, RS),也称栅格化、像素化,主要是为投影主屏幕上的3D三角形计算出对应的颜色
当裁剪操作完成之后,硬件会通过透视除法将物体从齐次裁剪空间变换为规格化设备坐标(NDC)。一旦物体的顶点位于 NDC 空间内,构成 2D 图像的 2D 顶点 x、y 坐标就会被变换到后台缓冲区称为视口的矩形里。这些 x、y 坐标都将以像素为单位,z坐标通常用作深度值
每个三角形都有两个面,假设三角形的顶点顺序为 v0,v1,v2
一般规定如果顶点绕序为顺时针的三角形为正面朝向,而顶点绕序为逆时针的三角形为背面朝向,摄像机将看不到实体对象中背面朝向的三角形,背面剔除就是用于将背面朝向的三角形从渲染流水线中除去的处理流程
Direct3D 可以通过设置将顺时针为正面的规则倒过来
顶点属性插值
顶点除了位置信息外还有颜色、法向量、纹理坐标等属性
经过视口变换之后,需要为求取三角形内所有像素所附的属性而进行插值运算
除了顶点属性,还需要对顶点的深度进行插值,继而得到每个像素参与实现深度缓冲的深度值
为了得到屏幕空间中各个顶点的插值属性,往往要通过一种名为透视矫正插值的方法,对3D空间中三角形的属性进行线性插值
像素着色器阶段
也称片段着色器
pixel shader PS 是一个中由 GPU 来执行的程序。它会针对每一个像素片段进行处理,并根据顶点的插值属性作为输入来计算出对应的像素颜色
像素着色器既可以直接返回一种单一的恒定颜色,也可以实现如逐像素光照、反射、以及阴影扽给更为复杂的效果
绘制几何体
顶点与输入布局
绘制几何体,首先就是要定义顶点,顶点不止存储位置信息,还有其他属性数据,所以定义一个结构体来表示顶点
struct Vertex1 {
XMFLOAT3 Pos; // 位置
XMFLOAT4 Color; // 颜色
}
struct Vertex2 {
XMFLOAT3 Pos; // 位置
XMFLOAT3 Normal; // 法线
XMFLOAT2 Tex0; // 纹理坐标
XMFLOAT2 Tex1; // 纹理坐标
}
使用 Vertex1[] 数组来存储顶点数据,那么 DirectX 如何这个数组应该如何解析呢?这个时候就需要使用输入布局描述
typedef struct D3D12_INPUT_ELEMENT_DESC
{
LPCSTR SemanticName; // 与元素相关联的特定字符串,传达了元素的预期用途
UINT SemanticIndex; // 附加到语义的索引
DXGI_FORMAT Format; // 指定元素格式 FLOAT、INT、UINT 等
UINT InputSlot; // 传递元素所用的输入槽
UINT AlignedByteOffset; // 某元素起始地址偏移
D3D12_INPUT_CLASSIFICATION InputSlotClass;
UINT InstanceDataStepRate;
} D3D12_INPUT_ELEMENT_DESC;

| 属性名 | SemanticName | SemanticIndex | Format | AlignedByteOffset |
|---|---|---|---|---|
| Pos | "Position" | 0 | DXGI_FORMAT_R32G32B32_FLOAT | 0 |
| Normal | "Normal" | 0 | DXGI_FORMAT_R32G32B32_FLOAT | 12 |
| Tex0 | "TEXCOORD" | 0 | DXGI_FORMAT_R32G32_FLOAT | 24 |
| Tex1 | "TEXCOORD" | 1 | DXGI_FORMAT_R32G32_FLOAT | 32 |
SemanticName主要用于表示用途,称之为语义SemanticIndex语义索引,故名思意与语义有关,当存在多个相同语义的属性时通过语义索引进行区分,所以Tex1的语义索引是 1Format表示数据类型,比如这里的DXGI_FORMAT_R32G32B32_FLOAT表示由三个32位浮点组成,DXGI_FORMAT_R32G32_FLOAT表示由两个32位浮点组成AlignedByteOffset表示地址偏移,如下图解释

Pos 和 Normal 分别由三个 32 位浮点组成,Tex0 和 Tex1 分别由两个 32 位浮点组成,所以 Vertex 总共由 10 个 32 位浮点组成
Pos属性相对Vertex首地址的内存偏移是0Normal属性相对Vertex首地址的内存偏移的一个 Pos 大小,也就是 3 个 32 位浮点,12 个字节Tex0属性相对Vertex首地址的内存偏移是 6 个 32 位浮点,也就是 24 字节Tex1属性相对Vertex首地址的内存偏移是 8 个 32 位浮点,也就是 32 字节
通过上述计算,可以得到 AlignedByteOffset 就是属性相对内存的偏移字节数
当得到一块 Vertex 的内存,通过 AlignedByteOffset 可以得到每个属性的起始地址,再通过 Format 可以得到每个属性的值
为了使 GPU 能够访问顶点数组,一般将顶点数据放在 GPU 资源的 缓冲区 里,一般称存放顶点的缓冲区域称为 顶点缓冲区 (Vertex Buffer)
与创建 深度缓冲区 类似,通过 D3D12_RESOURCE_DESC 来描述缓冲区资源,再通过 ID3D12Device::CreateCommitedResource 创建资源对象
对于静态几何体 (也就是每一帧都不会改变的几何体) 来说,会将其顶点缓冲区设置到 D3D12_HEAP_TYPE_DEFAULT 中来优化性能。对于这些静态物体,再顶点缓冲区初始化完毕之后,只有 GPU 需要从其中读取数据来绘制集合图
如果只有 GPU 能够读取数据,那么如何用 CPU 中的数据来初始化 GPU 中的顶点缓冲区呢?
这时会用到 D3D12_HEAP_TYPE_UPLOAD 堆类型来创建一个中介位置的上传缓冲区,这里的数据可以从 CPU 复制到 GPU 显存中,再通过上传缓冲区将数据复制到真正的顶点缓冲区中
上传堆在 CPU 管理的内存中,默认堆在 GPU 管理的显存中
Microsoft::WRL::ComPtr<ID3D12Resource> d3dUtil::CreateDefaultBuffer(
ID3D12Device* device,
ID3D12GraphicsCommandList* cmdList,
const void* initData,
UINT64 byteSize,
Microsoft::WRL::ComPtr<ID3D12Resource>& uploadBuffer)
{
ComPtr<ID3D12Resource> defaultBuffer;
// 创建 D3D12_HEAP_TYPE_DEFAULT 默认堆资源
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_COMMON,
nullptr,
IID_PPV_ARGS(defaultBuffer.GetAddressOf())));
// 创建 D3D12_HEAP_TYPE_UPLOAD 上传堆资源
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(uploadBuffer.GetAddressOf())));
D3D12_SUBRESOURCE_DATA subResourceData = {};
subResourceData.pData = initData;
subResourceData.RowPitch = byteSize;
subResourceData.SlicePitch = subResourceData.RowPitch;
// 设置 默认堆 资源转换屏障,表明资源将被用作拷贝目标
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
// 将数据从 initData 先复制到 CPU 的上传堆,再通过上传堆复制到 GPU 可见的 默认堆 中
UpdateSubresources<1>(cmdList, defaultBuffer.Get(), uploadBuffer.Get(), 0, 0, 1, &subResourceData);
// 设置 默认堆 资源转换评传,表明资源可以用于读取操作
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_GENERIC_READ));
return defaultBuffer;
}
为了不用每次数据上传到 GPU 都要写,于是封装了一层函数
通过上面的操作,成功将数据复制到 GPU 的默认堆中,并且通过输入布局告诉 D3D 如何解析数据
但是这些数据并没有绑定到渲染流水线上,渲染流水线与资源的绑定需要通过资源描述符,所以接下来需要创建顶点缓冲区视图(Vertex Buffer View)
我还是觉得一般来说视图(View)通常指的是描述符(Descriptor)
typedef struct D3D12_VERTEX_BUFFER_VIEW
{
D3D12_GPU_VIRTUAL_ADDRESS BufferLocation; // 待创建视图的顶点缓冲区资源虚拟地址,一般通过 ID3D12Resource::GetGPUVirtualAddress 获取
UINT SizeInBytes; // 顶点缓冲区大小 单位字节
UINT StrideInBytes; // 每个元素所占用的字节数 sizeof(Vertex)
} D3D12_VERTEX_BUFFER_VIEW;
通过 ID3D12GraphicsCommandList::IASetVertexBuffers 来绑定资源和输入槽
使用 ID3D12GraphicsCommandList::DrawInstanced 进行绘制
索引和索引缓冲区
如前面所说,为了防止顶点数据冗余,一般会设置顶点数组和索引数组,存储索引数组的缓冲区称为索引缓冲区
为了将索引缓冲区与渲染流水线绑定,所以要创建一个索引缓冲区视图
typedef struct D3D12_INDEX_BUFFER_VIEW
{
D3D12_GPU_VIRTUAL_ADDRESS BufferLocation; // 资源虚拟地址
UINT SizeInBytes; // 待创建的索引缓冲区大小 单位字节
DXGI_FORMAT Format; // 必须是 DXGI_FORMAT_R16_UINT 或者 DXGI_FORM_R32_UINT 根据索引数量决定
} D3D12_INDEX_BUFFER_VIEW;
与顶点缓冲区类似,需要将其绑定到渲染流水线上 ID3D12GraphicsCommandList::IASetIndexBuffer
然后使用 ID3D12GraphicsCommandList::DrawIndexedInstanced 进行绘制
virtual void STDMETHODCALLTYPE DrawIndexedInstanced(
_In_ UINT IndexCountPerInstance, // 将要绘制的索引数量
_In_ UINT InstanceCount, //
_In_ UINT StartIndexLocation, // 指向所以缓冲区中的某个元素,作为起始索引
_In_ INT BaseVertexLocation, // 在本次绘制调用读取顶点之前,要为每个索引都加上此值
_In_ UINT StartInstanceLocation) = 0;
为什么需要一个 StartIndexLocation 和 BaseVertexLocation 呢?
当前存在一个立方体、球体、圆柱体三种物体,处于性能问题,可以将零散顶点缓冲区和索引缓冲区进行合并
合并之后得到如下图所示的一块连续的顶点缓冲区 和 一块连续的顶点索引缓冲区

firstCylVertexPos 是圆柱体顶点缓冲区的起始序号 firstBoxVertexPos 是立方体顶点缓冲区的起始序号

numSphereIndices 是球形索引缓冲区中索引个数 numCylIndices 是圆柱体索引缓冲区中索引个数 numBoxIndices 是立方体索引缓冲区中索引个数
对于绘制球型来说
mCmdList->DrawIndexedInstanced(numSphereIndices, 1, 0, 0, 0);
对于绘制圆柱体来说
mCmdList->DrawIndexedInstanced(numCylIndices, 1, numSphereIndices, firstCylVertexPos, 0);
对于绘制立方体来说
mCmdList->DrawIndexedInstanced(numBoxIndices, 1, numCylIndices + numSphereIndices, firstCylVertexPos, 0);
顶点着色器
在 D3D 中,编写着色器的语言为高级着色器语言 (High Level Shading Language, HLSL)
// 顶点结构体
struct Vertex{
XMFLOAT3 Pos;
XMFLOAT4 Color;
}
// 输入结构描述符
D3D12_INPUT_ELEMENT_DESC inputLayout[] =
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 },
{ "COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 12, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 }
};
// HLSL 中顶点着色器(Vertex Shader)部分
void VS(float3 iPosL: POSITION, float4 iColor: COLOR, out float4 oPosH: SV_POSITION, out float4 oColor: COLOR) {
//
oPosH = mul(float4(iPosL, 1.0f), gWorldViewProj);
oColor = iColor;
}
Vertex 结构体中的 Pos 属性通过输入布局描述符中的 "POSITION" 与 HLSL 顶点着色器中的 float3 iPosL: POSITION 进行绑定的。同样,Vertex 结构体中的 Color 属性也是通过 "COLOR" 与 float4 iColor: COLOR 进行绑定的
注意
float3 iPosL: POSITION中的POSITION
这种绑定是通过输入布局描述符中的语义名称(如 "POSITION" 和 "COLOR")来实现的,它们与顶点着色器的输入参数中的语义标签相匹配。这样,当顶点缓冲区被送入 GPU 时,顶点着色器就能够根据这些语义名称接收到正确的数据
事实上,顶点数据与输入签名不需要完全匹配,前提是一定要向顶点着色器提供其输入签名所定义的顶点数据。也就是顶点着色器需要的数据必须提供
gWorldViewProj 存与常量缓冲区 (constant buffer) 中,内置函数 mul 用于计算矩阵长发
SV_POSITION 装饰的顶点着色器输出元素存有齐次裁剪空间中的顶点位置信息,因此必须要为输出位置信息的参数附上 SV_POSITION 语义,使得 GPU 可以在进行例如裁剪、深度测试和光栅化时,借此实现其他属性所无法接入的有关运算
SV_POSITION前面的SV表示System-Value即系统值
前面的 HLSL 代码可以改写成封装结构体的形式
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
struct VertexIn
{
float3 PosL : POSITION;
float4 Color : COLOR;
};
struct VertexOut
{
float4 PosH : SV_POSITION;
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);
vout.Color = vin.Color;
return vout;
}
关于 cbPerObject ,cbuffer 是 HLSL中的一个关键字,用于定义常量缓冲区(Constant Buffer)。常量缓冲区是一种特殊的资源,可以存储着色器中使用的常量数据,如变换矩阵、光照参数等。这些数据在渲染过程中不会改变,或者在多个渲染调用之间保持不变
使用 register(b0) 是为了指定常量缓冲区绑定到哪个寄存器。 b0 表示绑定到常量缓冲区寄存器槽 0。你可以使用其他寄存器,如 b1、b2 等,只要它们在你的着色器资源绑定计划中是可用的
定义 cbPerObject 是为了给常量缓冲区命名,并且在着色器代码中创建一个逻辑容器,这样可以更方便地组织和访问其中的常量数据。即使你可以直接使用 gWorldViewProj,但没有 cbuffer 的封装,你就无法将它作为一个整体传递到 GPU,也无法利用 HLSL 和图形 API 提供的常量缓冲区的优化
像素着色器
为了计算图元中每个像素的属性,会在光栅化处理期间堆顶点着色器输出的顶点属性进行插值。随后,再将这些插值数据传至像素着色器中,作为输入
在光栅化阶段,图元(如三角形)被转换成像素片段,每个片段对应屏幕上的一个像素。这时,像素着色器会为每个片段运行一次,以确定最终的像素颜色。如果多个图元覆盖同一个像素点,那么像素着色器可能会为该像素点运行多次,每次处理一个不同的片段
常量缓冲区
常量缓冲区(Constant Buffer)也是一种 GPU 资源,其数据内容可供着色器程序所引用
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
就是定义了一个名为 cbPerObject 的 cbuffer 常量缓冲区对象
在 Direct3D 12 中 HLSL 中可以通过定义单独的结构体,随后再用此结构体来创建一个常量缓冲区
struct ObjectConstants
{
float4x4 gWorldViewProj;
uint matIndex;
};
ConstantBuffer<ObjectConstants> gObjectConstants : register(b0);
uint index = gObjectConstants.matIndex;
与顶点缓冲区和索引缓冲区不同的是,常量缓冲区通常由 CPU 每帧更新。例如相机每帧都在不停的移动,那么常量缓冲区也需要在每一帧都随之以新的视图矩阵而更新。所以,一般把常量缓冲区创建到一个上传堆而非默认堆中,这样使得能从 CPU 端更新常量
常量缓冲区堆硬件也有特别的要求,即常量缓冲区的大小必为硬件最小分配空间(256B)的整数倍
static UINT CalcConstantBufferByteSize(UINT byteSize)
{
// ~ 表示取反位运算
return (byteSize + 255) & ~255;
}
绘制多个物体时,可能会需要多个相同类型的常量缓冲区,根据不同的物体而存储不同的数据。所以可以一次性创建多个 ObjectConstants 大小的空间,用于存储常量缓冲数组
struct ObjectConstants;
// 将大小变成 256 的倍数
UINT mElementByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(ObjectConstants));
ComPtr<D3D12Resource> mUploadCBuffer;
device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD);
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(mElementByteSize * NumElements),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&mUploadCBuffer)
);
由于是通过 D3D12_HEAP_TYPE_UPLOAD 来创建,所以可以通过 CPU 更新数据
首先听过 D3D12Resource::Map 获取指向资源中指定子资源的 CPU 指针
ComPtr<D3D12Resource> mUploadBuffer;
BYTE* mMappedData = nullptr;
mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mMappedData));
然后可以通过 memcpy 将系统数据复制到常量缓冲区中
memcpy(mMappedData, &data, dataSizeInBytes);
设置完毕之后,再通过 Unmap 取消映射
如果没有 Unmap 那么外界仍然能通过 mMappedData 来操作数据,比如绘制到一般时,数据发生了更改,这是很危险的
如果 Unmap 之后仍然想通过 mMappedData 来操作 Resource 也是很危险的,因为 DirectX 可能在运行时重新分配了内存
if(mUploadBuffer != nullptr) {
mUploadBuffer->Unmap(0, nullptr);
}
mMappedData = nullptr;
由于对于 上传堆 资源处理都是类似的,所以封装一个 UploadBuffer 类专门封装用于上传的资源
UploadBuffer(ID3D12Device* device, UINT elementCount, bool isConstantBuffer) :
mIsConstantBuffer(isConstantBuffer)
{
mElementByteSize = sizeof(T);
if(isConstantBuffer) {
mElementByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(T));
}
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(mElementByteSize*elementCount),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&mUploadBuffer)));
ThrowIfFailed(mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mMappedData)));
}
然后跟之前的深度模板视图一样,要创建一个对应的堆 D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV
D3D12_DESCRIPTOR_HEAP_DESC cbvHeapDesc;
cbvHeapDesc.NumDescriptors = 1;
cbvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
cbvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
cbvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(&cbvHeapDesc, IID_PPV_ARGS(&mCbvHeap)));
这里将
Flag设置为D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE,因为要给着色器程序访问
创建描述符堆之后,就是创建常量缓冲区描述符
通过填写 D3D12_Constant_BUFFER_VIEW_DESC 实例,调用 ID3D12Device::CreateConstantBufferView 来创建常量缓冲区
所以,一般流程代码如下
// 定义结构体
struct ObjectConstant {
XMFLOAT4X4 WorldViewProj = MathHelper::Identity4x4();
}
// 定义 n 个常量缓冲区存储常量数据
std::unique_ptr<UploadBuffer<ObjectConstant>> mObjectCB = nullptr;
mObjectCB = std::make_unique<UploadBuffer<ObjectConstant>>(md3dDevice.Get(), n, true);
// 得到实际大小 至少得是 256 的倍数
UINT objCBByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(ObjectConstant));
// 得到缓冲区的起始地址
D3D12_GPU_VAITUAL_ADDRESS cbAddress = mObjectCB->Resource()->GetGPUVirtualAddress();
// 得到第 i 个缓冲区偏移
int boxCBufIndex = i;
cbAddresss += boxCBufIndex * objCBByteSize;
D3D12_CONSTANT_BUFFER_VIEW_DESC cbvDesc;
cbvDesc.BufferLocation = cbAddress;
cbvDesc.SizeInBytes = objCBByteSize;
// 创建资源描述符
md3dDevice->CreateConstantBufferView(&cbvDesc, mCbvHeap->GetCPUDescriptionHandleForHeapStart());
在绘制开始之前,会将着色器程序所需的各种类型的资源绑定到渲染流水上。实际上,不同的资源会被绑定到特定的寄存器槽(register slot) 上,以供着色器访问
// 纹理寄存器 槽 0
Texture2D gDiffuseMap : register(t0);
// 采样寄存器 槽 0 ~ 5
SmaplerState gsamPointWrap : register(s0);
SmaplerState gsamPointClamp : register(s1);
SmaplerState gsamLinearWrap : register(s2);
SmaplerState gsamLinearCalmp : register(s3);
SmaplerState gsamAnisotropicWrap : register(s4);
SmaplerState gsamAnisotropicClamp : register(s5);
// 常量缓冲区 槽 0
cbuffer cbPerObject : register(b0) {
float4x4 gWorld;
}
// 常量缓冲区 槽 1
cbuffer cbPass : register(b1) {
float4x4 gView;
}
使用 *根签名 (root signature) 来定义着色器程序与应用程序之间的接口。根签名定义了哪些资源(常量缓冲区、纹理、采样器等)可以被绑定,并且指明了如何在着色器程序中访问这些资源
在执行绘制命令之前,那些应用程序将绑定到渲染流水线上的资源,他们会被映射到着色器的对应输入寄存器。所以根签名一定要与使用它的着色器相兼容,在创建流水线状态对象(Pipeline State Object)时会对此进行验证
不同的绘制调用可能会用到一组不同的着色器程序,这也就意味着要用到不同的根签名
根签名 由 ID3D12RootSignature 表示
根签名由一个或多个根参数(Root Parameters)组成,这些参数可以是以下几种类型之一:
根常量(Root Constants):
- 直接在根签名中包含的少量常量数据(比如一些转换矩阵或光照参数)
- 这些常量可以直接由着色器访问,无需通过任何缓冲区
根描述符(Root Descriptors):
- 单个的描述符,可以是常量缓冲区视图(CBV)、着色器资源视图(SRV)或无序访问视图(UAV)
- 提供比根常量更大的灵活性,可以直接绑定一个缓冲区或纹理
根描述符表(Root Descriptor Tables):
- 这是一个指向多个描述符的指针数组(例如多个缓冲区或纹理),这些描述符组织在一个或多个描述符堆中
- 适用于需要访问大量资源的情况
void BoxApp::BuildRootSignature()
{
CD3DX12_ROOT_PARAMETER slotRootParameter[1];
CD3DX12_DESCRIPTOR_RANGE cbvTable;
// D3D12_DESCRIPTOR_RANGE_TYPE_CBV:指定这个描述符范围的类型是CBV。这意味着这个范围内的描述符都是常量缓冲视图。
// 1:这个数字表示范围内描述符的数量。这里是1,意味着这个范围包含一个CBV。
// 0:这是描述符在根签名中的基础寄存器索引。这里的0表示这个CBV从寄存器 b0 开始。
cbvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 0);
slotRootParameter[0].InitAsDescriptorTable(1, &cbvTable);
// Something Else
ThrowIfFailed(md3dDevice->CreateRootSignature(
0,
serializedRootSig->GetBufferPointer(),
serializedRootSig->GetBufferSize(),
IID_PPV_ARGS(&mRootSignature)));
}
创建根签名之后,在绘制时通过命令与具体的视图进行绑定
ID3D12DescriptorHeap* descriptorHeaps[] = { mCbvHeap.Get() };
mCommandList->SetDescriptorHeaps(_countof(descriptorHeaps), descriptorHeaps);
mCommandList->SetGraphicsRootSignature(mRootSignature.Get());
// 这行代码将描述符堆中的描述符绑定到根签名的一个特定槽位 这里是槽位0
mCommandList->SetGraphicsRootDescriptorTable(0, mCbvHeap->GetGPUDescriptorHandleForHeapStart());
SetDescriptorHeaps:在这里,mCbvHeap 是用来告诉命令列表,接下来的绘制命令将会使用哪些描述符堆SetGraphicsRootDescriptorTable:在这里,使用mCbvHeap来指定具体的描述符(从堆的起始位置开始)绑定到根签名的哪个槽位
GetGPUDescriptorHandleForHeapStart 第一参数 0,表示槽位 0,也就是 slotRootParameter[0]
编译着色器
Direct3D 中,着色器程序必须先被编译为一种可移植的字节码。然后图形驱动程序将获取这些字节码,并将其重新编译为针对当前系统 GPU 所优化的本地指令
HRESULT D3DCompileFromFile(
[in] LPCWSTR pFileName, // 希望编译的以 .hlsl 作为扩展名的 HLSL 源码文件
[in, optional] const D3D_SHADER_MACRO *pDefines, // 高级选项,不使用时填写 nullptr
[in, optional] ID3DInclude *pInclude, // 高级选项,不使用时填写 nullptr
[in] LPCSTR pEntrypoint, // 着色器函数的入口点函数名
[in] LPCSTR pTarget, // 指定着色器类型和版本
[in] UINT Flags1, // 如何编译的标志
[in] UINT Flags2, // 高级编译选项
[out] ID3DBlob **ppCode, // 指向 ID3DBlob 数据结构的指针,存储编译好的字节码
[out, optional] ID3DBlob **ppErrorMsgs // 指向 ID3DBlob 数据结构的指针,如果发生错误会存储报错的字符串
);
ID3DBlob 就是一段普通的字符串,通过 GetBufferPointer 可以获得 void* 类型的指针,需要自己手动转换;通过 GetBufferSize 可以获得缓冲区的字节大小
ComPtr<ID3DBlob> d3dUtil::CompileShader(const std::wstring& filename, const D3D_SHADER_MACRO* defines, const std::string& entrypoint, const std::string& target)
{
UINT compileFlags = 0;
#if defined(DEBUG) || defined(_DEBUG)
compileFlags = D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION;
#endif
HRESULT hr = S_OK;
ComPtr<ID3DBlob> byteCode = nullptr;
ComPtr<ID3DBlob> errors;
hr = D3DCompileFromFile(filename.c_str(), defines, D3D_COMPILE_STANDARD_FILE_INCLUDE, entrypoint.c_str(), target.c_str(), compileFlags, 0, &byteCode, &errors);
if(errors != nullptr) {
OutputDebugStringA((char*)errors->GetBufferPointer());
}
ThrowIfFailed(hr);
return byteCode;
}
除了运行时编译着色器,还能够以单独的步骤离线的编译着色器
- 复杂的着色器编译时间长,离线编译可以缩短程序加载时间
- 提前编译可以提前发现错误
通常用 .cso (compiled shader object) 作为以编译着色器的扩展名
可以使用 DirectX 自带的 FXC 命令行编译工具来离线的编译着色器
在程序运行时,可以通过标准文件输入机制来将 cso 中编译好的字节码加载到应用程序中
ComPtr<ID3DBlob> d3dUtil::LoadBinary(const std::wstring& filename)
{
std::ifstream fin(filename, std::ios::binary);
fin.seekg(0, std::ios_base::end);
std::ifstream::pos_type size = (int)fin.tellg();
fin.seekg(0, std::ios_base::beg);
ComPtr<ID3DBlob> blob;
ThrowIfFailed(D3DCreateBlob(size, blob.GetAddressOf()));
fin.read((char*)blob->GetBufferPointer(), size);
fin.close();
return blob;
}
光栅器状态
渲染流水线中大多阶段是可编程的,但是一些阶段只能接受配置
用来配置渲染流水线中光栅化阶段的光栅器状态组由结构体 D3D12_RASTERIZER_DESC 来表示
typedef struct D3D12_RASTERIZER_DESC {
D3D12_FILL_MODE FillMode; // 实体模式或线框模式渲染
D3D12_CULL_MODE CullMode; // 不绘制指定朝向的三角形,比如正面、背面、或者都渲染
BOOL FrontCounterClockwise; // true 表示顶点逆时针构成的三角形为证明;false 则相反
INT DepthBias; //
FLOAT DepthBiasClamp; //
FLOAT SlopeScaledDepthBias; //
BOOL DepthClipEnable; //
BOOL MultisampleEnable; //
BOOL AntialiasedLineEnable; //
UINT ForcedSampleCount; //
D3D12_CONSERVATIVE_RASTERIZATION_MODE ConservativeRaster; //
} D3D12_RASTERIZER_DESC;
流水线状态对象
前面创建了输入布局描述、顶点着色器、像素着色器,配置了光栅器状态组,那么现在问题来了,怎么将这些对象绑定到图形流水线上,用以实际绘制图形
大多数控制图形流水线状态的对象被统称为流水线状态对象(Pipeline State Object)
在 D3D 中使用 ID3D12PipelineState 接口表示 PSO 对象,要创建 PSO 对象需要填写详细的 D3D12_GRAPHICS_PIPELINE_STATE_DESC
typedef struct D3D12_GRAPHICS_PIPELINE_STATE_DESC {
ID3D12RootSignature *pRootSignature; // 根签名
D3D12_SHADER_BYTECODE VS; // 顶点着色器字节码
D3D12_SHADER_BYTECODE PS; // 像素着色器
D3D12_SHADER_BYTECODE DS; // 域着色器
D3D12_SHADER_BYTECODE HS; // 外壳着色器
D3D12_SHADER_BYTECODE GS; // 几何着色器
D3D12_STREAM_OUTPUT_DESC StreamOutput; //
D3D12_BLEND_DESC BlendState; // 指定混合操作所用的混合状态
UINT SampleMask; // 多重采样技术最多可采集32个样本,不想采集某个样本则二进制对应位置为0
D3D12_RASTERIZER_DESC RasterizerState; // 光栅器的光栅化状态
D3D12_DEPTH_STENCIL_DESC DepthStencilState; // 深度.模板状态
D3D12_INPUT_LAYOUT_DESC InputLayout; // 输入布局描述
D3D12_INDEX_BUFFER_STRIP_CUT_VALUE IBStripCutValue; // 索引缓冲区的属性
D3D12_PRIMITIVE_TOPOLOGY_TYPE PrimitiveTopologyType; // 图元拓扑类型
UINT NumRenderTargets; // RTVFormats 成员中呈现目标格式的数目
DXGI_FORMAT RTVFormats[8]; // 渲染目标格式
DXGI_FORMAT DSVFormat; // 深度模板缓冲区格式
DXGI_SAMPLE_DESC SampleDesc; // 多重采样堆每个像素采样的数量及质量级别
UINT NodeMask; // 对于单个 GPU 操作,请将此设置为零
D3D12_CACHED_PIPELINE_STATE CachedPSO; // 缓存的管道状态对象
D3D12_PIPELINE_STATE_FLAGS Flags; //
} D3D12_GRAPHICS_PIPELINE_STATE_DESC;
ID3D12PipelineState 集合了大量流水线状态信息,为了保证性能,将所有这些对象都集中在一起,一并送到渲染流水线
Direct3D 本质上是一种状态机
mCommandList->SetPipllineState(mPso1.Get());
// 使用 PSO1 绘制物体
mCommandList->SetPipllineState(mPso2.Get());
// 使用 PSO2 绘制物体
在使用 PSO2 修改流水线状态之前,会一直用 PSO1 的配置进行渲染流水线
几何图形辅助函数
// 结构体定义了一个几何子网格
struct SubmeshGeometry
{
UINT IndexCount = 0; // 需要绘制的索引数量
UINT StartIndexLocation = 0; // 在索引缓冲区中,绘制操作应该开始读取索引的起始位置
INT BaseVertexLocation = 0; // 顶点缓冲区中的基础顶点位置
DirectX::BoundingBox Bounds; // 此子网格的边界盒,在进行如视锥裁剪等操作时非常有用
};
// 存储和管理与一组几何数据相关的所有资源和状态的容器
struct MeshGeometry {
std::string Name; // 几何体的名称,用于通过名称索引查找具体的几何体
Microsoft::WRL::ComPtr<ID3DBlob> VertexBufferCPU = nullptr; // 顶点和索引数据的系统内存副本,方便CPU访问
Microsoft::WRL::ComPtr<ID3DBlob> IndexBufferCPU = nullptr; //
Microsoft::WRL::ComPtr<ID3D12Resource> VertexBufferGPU = nullptr; // 上传到GPU的顶点和索引缓冲区
Microsoft::WRL::ComPtr<ID3D12Resource> IndexBufferGPU = nullptr; //
Microsoft::WRL::ComPtr<ID3D12Resource> VertexBufferUploader = nullptr; // 将数据从CPU传输到GPU的上传缓冲区
Microsoft::WRL::ComPtr<ID3D12Resource> IndexBufferUploader = nullptr; // 将数据从CPU传输到GPU的上传缓冲区
UINT VertexByteStride = 0; // 缓冲区的布局和格式
UINT VertexBufferByteSize = 0; //
DXGI_FORMAT IndexFormat = DXGI_FORMAT_R16_UINT; //
UINT IndexBufferByteSize = 0; //
std::unordered_map<std::string, SubmeshGeometry> DrawArgs; // 按名称访问各个子网格,每个子网格可以单独绘制
}
通过上述结构体,可以方便的定义一个具有多个子几何体的几何体,下面以一个立方体为例
std::array<Vertex, 8> vertices =
{
Vertex({ XMFLOAT3(-1.0f, -1.0f, -1.0f), XMFLOAT4(Colors::White) }),
Vertex({ XMFLOAT3(-1.0f, +1.0f, -1.0f), XMFLOAT4(Colors::Black) }),
Vertex({ XMFLOAT3(+1.0f, +1.0f, -1.0f), XMFLOAT4(Colors::Red) }),
Vertex({ XMFLOAT3(+1.0f, -1.0f, -1.0f), XMFLOAT4(Colors::Green) }),
Vertex({ XMFLOAT3(-1.0f, -1.0f, +1.0f), XMFLOAT4(Colors::Blue) }),
Vertex({ XMFLOAT3(-1.0f, +1.0f, +1.0f), XMFLOAT4(Colors::Yellow) }),
Vertex({ XMFLOAT3(+1.0f, +1.0f, +1.0f), XMFLOAT4(Colors::Cyan) }),
Vertex({ XMFLOAT3(+1.0f, -1.0f, +1.0f), XMFLOAT4(Colors::Magenta) })
};
std::array<std::uint16_t, 36> indices =
{
// front face
0, 1, 2,
0, 2, 3,
// back face
4, 6, 5,
4, 7, 6,
// left face
4, 5, 1,
4, 1, 0,
// right face
3, 2, 6,
3, 6, 7,
// top face
1, 5, 6,
1, 6, 2,
// bottom face
4, 0, 3,
4, 3, 7
};
vertices 定义了立方体的八个顶点, indices 定义了立方体的六个面,一个面由两个三角形组成
接下来就是将数据保存到 MeshGeometry 对象中
获得几何体内存大小
const UINT vbByteSize = (UINT)vertices.size() * sizeof(Vertex);
const UINT ibByteSize = (UINT)indices.size() * sizeof(std::uint16_t);
通过几何体大小创建 CPU 可访问的 Buffer
D3DCreateBlob(vbByteSize, &mBoxGeo->VertexBufferCPU);
CopyMemory(mBoxGeo->VertexBufferCPU->GetBufferPointer(), vertices.data(), vbByteSize);
D3DCreateBlob(ibByteSize, &mBoxGeo->IndexBufferCPU);
CopyMemory(mBoxGeo->IndexBufferCPU->GetBufferPointer(), indices.data(), ibByteSize);
通过 d3dUtil::CreateDefaultBuffer 创建 上传堆 和 默认堆,将数据从内存中通过上传堆转到显存中供 GPU 使用
mBoxGeo->VertexBufferGPU = d3dUtil::CreateDefaultBuffer(md3dDevice.Get(),
mCommandList.Get(), vertices.data(), vbByteSize, mBoxGeo->VertexBufferUploader);
mBoxGeo->IndexBufferGPU = d3dUtil::CreateDefaultBuffer(md3dDevice.Get(),
mCommandList.Get(), indices.data(), ibByteSize,mBoxGeo->IndexBufferUploader);
定义布局,帮助解释内存布局
mBoxGeo->VertexByteStride = sizeof(Vertex); // 步长
mBoxGeo->VertexBufferByteSize = vbByteSize; // 大小
mBoxGeo->IndexFormat = DXGI_FORMAT_R16_UINT; // 结构
mBoxGeo->IndexBufferByteSize = ibByteSize; // 大小
定义子模型的大小,由于这里只有一个立方体,所以只有一个子模型
SubmeshGeometry submesh;
submesh.IndexCount = (UINT)indices.size(); // 子模型索引个数
submesh.StartIndexLocation = 0; // 子模型索引起始序号
submesh.BaseVertexLocation = 0; // 子模型顶点起始序号
mBoxGeo->DrawArgs["box"] = submesh;
绘制 Box
根据前面的描述,在初始化的还需要
- 创建常量描述符堆,创建常量描述符
- 创建根签名
- 编译 Shader
- 设置输入布局
- 设置顶点缓冲和索引缓冲
- 创建光栅器状态对象,并创建 PSO 流水线状态对象
bool D3DBox::Initialize()
{
if (!D3DApp::Initialize())
return false;
ThrowIfFailed(mCommandList->Reset(mCommandAllocator.Get(), nullptr));
BuildDescriptorHeaps(); // 创建常量描述符堆
BuildConstantBuffers(); // 创建常量缓冲区
BuildRootSignature(); // 创建根签名
BuildShaderAndInputLayout(); // 编译 Shader 设置输入布局
BuildBoxGeometry(); // 设置 Box 数据
BuildPSO(); // 创建 光栅化状态对象 和 PSO 对象
ThrowIfFailed(mCommandList->Close());
ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
FlushCommandQueue();
return true;
}
除了 D3D 相关数据初始化之外,相机的坐标、角度等也需要计算
int D3DApp::Run()
{
MSG msg{ 0 };
mTimer.Reset();
while (msg.message != WM_QUIT)
{
if (PeekMessage(&msg, 0, 0, 0, PM_REMOVE)) {
TranslateMessage(&msg);
DispatchMessage(&msg);
}
else {
mTimer.Tick();
if (!mAppPaused) {
CalculateFrameState();
Update(mTimer);
Draw(mTimer);
}
else {
Sleep(100);
}
}
}
return 0;
}
一般来说系统的运行流程如上所示,有事件(鼠标、键盘输入)处理事件,没事件先执行 Update 再执行 Draw
Update 中更新数据,Draw 中调用命令绘制画面
如果先执行 Draw,此时数据都没有初始化或者设置,绘制没有任何意义
所以此时还需要在 Update 中更新一些数据,比如设置相机和对象的变换矩阵
这里相机使用的是球坐标系,使用相机距离目标点(原点)的半径、极角和方位角即可定义相机坐标
方位角: 这是一个水平角度,表示从参考方向(通常是x轴正方向)到点在水平平面上投影的线之间的角度。在直角坐标系中,它对应于点在xy平面上的位置
极角: 这是一个垂直角度,表示从正z轴到点的连线与z轴之间的角度。它描述了点相对于水平面的高度

如上图所示,r 表示半径, $\phi$ 表示极角, $\theta$ 表示方位角,通过这三个数据可以得到相机在世界坐标系下的坐标
float x = mRadius * sinf(mPhi) * cosf(mTheta);
float z = mRadius * sinf(mPhi) * sinf(mTheta);
float y = mRadius * cosf(mPhi);
使用球坐标系有方便计算相机绕点旋转、避免万向锁、方便交互等好处,具体情况可以根据实际开发需求进行变换
知道相机坐标之后定义视图矩阵,pos 表示相机坐标、target 表示目标点向量、up 表示相机的上方向向量
XMVECTOR pos = XMVectorSet(x, y, z, 1.0f);
XMVECTOR target = XMVectorZero();
XMVECTOR up = XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f);
XMMATRIX view = XMMatrixLookAtLH(pos, target, up);
通过 target 点和 pos 点可以定义相机的朝向也就是 Pitch 和 Yaw,通过 up 向量可以定义相机的 Roll
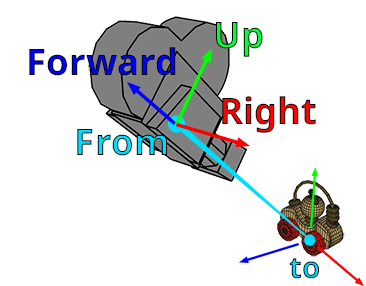
接下来就是构建世界-视图-投影矩阵,用于计算物体坐标
物体中顶点坐标都是物体坐标系
- 通过世界矩阵将物体从局部坐标系转换到世界坐标系
- 通过视图矩阵将物体从世界坐标系转换到相机坐标系
- 通过投影矩阵将物体从相机坐标系转换到裁剪空间
通过 世界-视图-投影 矩阵可以将物体从局部坐标转换到最终的 2D 屏幕坐标
$\text{屏幕坐标} = \text{投影矩阵} \times \text{视图矩阵} \times \text{世界矩阵} \times \text{模型坐标}$
XMStoreFloat4x4(&mView, view);
XMMATRIX world = XMLoadFloat4x4(&mWorld);
XMMATRIX proj = XMLoadFloat4x4(&mProj);
XMMATRIX worldViewProj = world * view * proj;
ObjectConstants objConstants;
XMStoreFloat4x4(&objConstants.WorldViewProj, XMMatrixTranspose(worldViewProj));
mObjectCB->CopyData(0, objConstants);
通过上述步骤计算得到一个可以一次将坐标变换到屏幕坐标的矩阵,并将其存储到了 ConstantBuffer 中
在顶点着色器中可以直接使用该矩阵进行计算
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);
更新完数据之后,就需要根据已有数据进行渲染
void D3DBox::Draw(const GameTimer& gt)
{
// 重设命令
ThrowIfFailed(mCommandAllocator->Reset());
ThrowIfFailed(mCommandList->Reset(mCommandAllocator.Get(), mPSO.Get()));
// 设置视口和窗口大小 RS 表示 Rasterizer Stage 光栅化阶段
mCommandList->RSSetViewports(1, &mScreenViewport);
mCommandList->RSSetScissorRects(1, &mScissorRect);
// 设置 Buffer 为可以写入 RenderTarget
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET));
// 清空 RTV
mCommandList->ClearRenderTargetView(CurrentBackBufferView(), Colors::LightSteelBlue, 0, nullptr);
// 清空 DSV
mCommandList->ClearDepthStencilView(DepthStencilView(), D3D12_CLEAR_FLAG_DEPTH | D3D12_CLEAR_FLAG_STENCIL, 1.0f, 0, 0, nullptr);
// 设置 RT
mCommandList->OMSetRenderTargets(1, &CurrentBackBufferView(), true, &DepthStencilView());
// 设置描述符堆
ID3D12DescriptorHeap* descriptorHeaps[] = { mCbvHeap.Get() };
mCommandList->SetDescriptorHeaps(_countof(descriptorHeaps), descriptorHeaps);
// 设置根签名
mCommandList->SetGraphicsRootSignature(mRootSignature.Get());
// 设置顶点、顶点索引、绘制图形
mCommandList->IASetVertexBuffers(0, 1, &mBoxGeo->VertexBufferView());
mCommandList->IASetIndexBuffer(&mBoxGeo->IndexBufferView());
mCommandList->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
// 设置常量缓冲区到根签名表中的第0个
mCommandList->SetGraphicsRootDescriptorTable(0, mCbvHeap->GetGPUDescriptorHandleForHeapStart());
// 绘制 Box
mCommandList->DrawIndexedInstanced(mBoxGeo->DrawArgs["box"].IndexCount, 1, 0, 0, 0);
// 重新设置 Buffer 状态
mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT));
// 关闭命令
ThrowIfFailed(mCommandList->Close());
// 执行命令
ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
// 将缓冲区显示到屏幕上
ThrowIfFailed(mSwapChain->Present(0, 0));
// 重新设置后台缓冲区序号,因为当前缓冲区已经由于显示了,所以得换一个缓冲区
mCurrentBackBuffer = (mCurrentBackBuffer + 1) % SwapChainBufferCount;
// 等待命令执行完毕
FlushCommandQueue();
}
当屏幕中绘制玩立方体之后,可以通过鼠标来控制旋转和远近,通过相机的球形坐标系,可以很方便的实现相机绕原点旋转的效果
void D3DBox::OnMouseDown(WPARAM btnState, int x, int y)
{
mLastMousePos.x = x;
mLastMousePos.y = y;
SetCapture(mhMainWnd);
}
void D3DBox::OnMouseUp(WPARAM btnState, int x, int y)
{
ReleaseCapture();
}
通过 SetCapture 可以将所有的鼠标消息发送到这个窗口,ReleaseCapture 则释放鼠标捕获
void D3DBox::OnMouseMove(WPARAM btnState, int x, int y)
{
if ((btnState & MK_LBUTTON) != 0)
{
float dx = XMConvertToRadians(0.25f * static_cast<float>(x - mLastMousePos.x));
float dy = XMConvertToRadians(0.25f * static_cast<float>(y - mLastMousePos.y));
mTheta += dx;
mPhi += dy;
mPhi = MathHelper::Clamp(mPhi, 0.1f, MathHelper::Pi - 0.1f);
}
else if ((btnState & MK_RBUTTON) != 0)
{
float dx = 0.005f * static_cast<float>(x - mLastMousePos.x);
float dy = 0.005f * static_cast<float>(y - mLastMousePos.y);
mRadius += dx - dy;
mRadius = MathHelper::Clamp(mRadius, 3.0f, 15.0f);
}
mLastMousePos.x = x;
mLastMousePos.y = y;
}
在鼠标移动的时候根据是否按下 MK_LBUTTON 或 MK_RBUTTON 来调整 mRadius 值 或者 mTheta、mPhi 值
绘制几何体(序)
帧资源
CPU 除了执行必要的工作之外,还要构建并提交命令列表
GPU 负责处理命令队列中的各种命令
D3DBox 在绘制每一帧时都会将 CPU 和 GPU 进行一次同步
- GPU 未结束命令分配器中所有命令的执行之前不能将它重置,如果不同步那么 GPU 命令可能并没有执行完毕,CPU 就已经重置了命令分配器
- GPU 未完成与常量缓冲区相关的绘制明林之前,CPU 不可以更新常量缓冲区
所以每次绘制的结尾都要执行 D3DApp::FlushCommandQueue 函数来确保 GPU 每帧都能正确完成所有命令,但是这种做法效率低下
- 每帧的起始阶段, GPU 不会执行任何命令,因为命令队列空空如也
- 每帧的结束阶段, CPU 会等到 CPU 执行完毕
所以上述同步的做法 CPU 和 GPU 每一帧存在空闲时间
于是,将 CPU 每帧都需要更新的资源作为基本元素,创建一个环形数组(circular array),成这些资源为帧资源(frame resource),这种循环数组通常是由 3 个帧资源元素所构成
处理第 n 帧的时候, CPU 将周而复始的从帧资源数组中获取下一个可用的(没被 GPU 使用)帧资源。趁着 GPU 处理此前帧的时候, CPU 将为第 n 帧更新资源,并构建和提交对应的命令队列
随后 CPU 继续针对第 n+1 帧执行同样的工作流程,并不断重复下去
如果帧资源数组共有 3 个元素,则令 CPU 比 GPU 提前两帧处理
struct FrameResource
{
public:
FrameResource(ID3D12Device* device, UINT passCount, UINT objectCount);
FrameResource(const FrameResource& rhs) = delete;
FrameResource& operator=(const FrameResource& rhs) = delete;
~FrameResource();
// 在 GPU 处理完与此命令分配器相关的命令之前,不会对其进行重置,所以每一帧都要有自己的命令分配器
Microsoft::WRL::ComPtr<ID3D12CommandAllocator> CmdListAlloc;
// 在 CPU 执行完运用此常量缓冲区的命令之前,不会对其进行更新,所以每一帧都要有自己的常量缓冲区
std::unique_ptr<UploadBuffer<PassConstants>> PassCB = nullptr;
std::unique_ptr<UploadBuffer<ObjectConstants>> ObjectCB = nullptr;
// 通过围栏值命令标记到此围栏点,可以检测到 GPU 是否还在使用这些帧资源
UINT64 Fence = 0;
};
定义帧资源数组
FrameResource* mCurrFrameResource = nullptr;
int mCurrFrameResourceIndex = 0;
std::vector<std::unique_ptr<FrameResource>> mFrameResources;
void ShapesApp::BuildFrameResources()
{
for(int i = 0; i < gNumFrameResources; ++i)
{
mFrameResources.push_back(std::make_unique<FrameResource>(md3dDevice.Get(),
1, (UINT)mAllRitems.size()));
}
}
CPU 使用帧资源数组
void ShapesApp::Update(const GameTimer& gt) {
// 获取帧资源循环数组中的元素
mCurrFrameResourceIndex = (mCurrFrameResourceIndex + 1) % gNumFrameResources;
mCurrFrameResource = mFrameResources[mCurrFrameResourceIndex].get();
// 判断当前帧资源是否执行完毕,如果没有 CPU 等待 GPU 执行完命令
if(mCurrFrameResource->Fence != 0 && mFence->GetCompletedValue() < mCurrFrameResource->Fence)
{
HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS);
ThrowIfFailed(mFence->SetEventOnCompletion(mCurrFrameResource->Fence, eventHandle));
WaitForSingleObject(eventHandle, INFINITE);
CloseHandle(eventHandle);
}
// Do Something
}
GPU 定义新的围栏值
void ShapesApp::Draw(const GameTimer& gt) {
// DO Somehting
// 增加围栏值
mCurrFrameResource->Fence = ++mCurrentFence;
// 向命令队列增加一条指令来设置新的围栏点
// 由于 GPU 正在执行绘制命令,所以在 GPU 执行完 Signal 之前的命令之前不会设置新的围栏点
mCommandQueue->Signal(mFence.Get(), mCurrentFence);
}
虽然使用了帧资源数组,但是该解决方案还是无法避免等待情况的发生,如果两种处理器处理帧的速度过大,则前者终将不得不等待后来者的追上
如果 CPU 处理帧的熟读总是遥遥领先与 GPU,则 CPU 一定存在等待时间,而这个时间可以利用 CPU 运行游戏的其他部分(AI、物理模拟、游戏逻辑业务等)
渲染项
绘制一个物体需要设置多种参数,例如绑定顶点缓冲区、索引缓冲区、常量数据、图元类型等
随着场景中所绘制物体的逐渐增多,使用一个轻量级结构来存储绘制物体所需的数据进行。一般把单词绘制调用过程中,需要向渲染流水线提交的数据集称为渲染项
根据不同的应用程序会有所差别
struct RenderItem
{
RenderItem() = default;
// 局部空间相对世界空间的世界矩阵 定义了物体位于世界空间中的位置、朝向以及大小
XMFLOAT4X4 World = MathHelper::Identity4x4();
//
int NumFramesDirty = gNumFrameResources;
// 该索引指向的 GPU 常量缓冲区对于当前渲染项中的物体常量缓冲区
UINT ObjCBIndex = -1;
// 此渲染项参与绘制的几何体,绘制一个几何体可能会用到多个渲染项
MeshGeometry* Geo = nullptr;
// 图元拓扑
D3D12_PRIMITIVE_TOPOLOGY PrimitiveType = D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST;
// DrawIndexedInstanced 方法的参数
UINT IndexCount = 0;
UINT StartIndexLocation = 0;
int BaseVertexLocation = 0;
};
渲染过程中所用到的常量数据
struct PassConstants
{
DirectX::XMFLOAT4X4 View = MathHelper::Identity4x4();
DirectX::XMFLOAT4X4 InvView = MathHelper::Identity4x4();
DirectX::XMFLOAT4X4 Proj = MathHelper::Identity4x4();
DirectX::XMFLOAT4X4 InvProj = MathHelper::Identity4x4();
DirectX::XMFLOAT4X4 ViewProj = MathHelper::Identity4x4();
DirectX::XMFLOAT4X4 InvViewProj = MathHelper::Identity4x4();
DirectX::XMFLOAT3 EyePosW = { 0.0f, 0.0f, 0.0f };
float cbPerObjectPad1 = 0.0f;
DirectX::XMFLOAT2 RenderTargetSize = { 0.0f, 0.0f };
DirectX::XMFLOAT2 InvRenderTargetSize = { 0.0f, 0.0f };
float NearZ = 0.0f;
float FarZ = 0.0f;
float TotalTime = 0.0f;
float DeltaTime = 0.0f;
};
随着项目复杂度的增加,缓冲区中存储的数据内容会根据特定的渲染过程而确定下来
其中包含了与游戏计时有关的信息,时着色器程序中要访问的极其有用的数据
cbuffer cbPass : register(b1)
{
float4x4 gView;
float4x4 gInvView;
float4x4 gProj;
float4x4 gInvProj;
float4x4 gViewProj;
float4x4 gInvViewProj;
float3 gEyePosW;
float cbPerObjectPad1;
float2 gRenderTargetSize;
float2 gInvRenderTargetSize;
float gNearZ;
float gFarZ;
float gTotalTime;
float gDeltaTime;
};
此时,为了绘制物体,唯一与之相关的变量就是世界矩阵
cbuffer cbPerObject : register(b0)
{
float4x4 gWorld;
};
基于资源的更新频率对常量数据进行分组,每次渲染过程中,只需要将本次所用的常量 cbPass 更新一次;当物体的世界矩阵发生改变时,只需要更新该物体的相关常量(cbPerObject)即可
由于得到的是世界坐标矩阵和裁剪矩阵两个矩阵,对应的顶点着色器也要做修改
VertexOut VS(VertexIn vin)
{
VertexOut vout;
// 变换到齐次世界坐标系
float4 posW = mul(float4(vin.PosL, 1.0f), gWorld);
// 变换到裁剪坐标系
vout.PosH = mul(posW, gViewProj);
vout.Color = vin.Color;
return vout;
}
D3DBox中一步到位是因为存储的的是 世界-视图-矩阵
由于现在需要两个常量缓冲区来存储数据信息,所以根签名也要做出对应的修改
CD3DX12_DESCRIPTOR_RANGE cbvTable0;
// 存储到 b0 寄存器
cbvTable0.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 0);
CD3DX12_DESCRIPTOR_RANGE cbvTable1;
// 存储到 b1 寄存器
cbvTable1.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 1);
CD3DX12_ROOT_PARAMETER slotRootParameter[2];
slotRootParameter[0].InitAsDescriptorTable(1, &cbvTable0);
slotRootParameter[1].InitAsDescriptorTable(1, &cbvTable1);
CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(2, slotRootParameter, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
不同形状的几何体
简单封装一个 GeometryGenerator 用于生成一些模型顶点,比如球、圆柱、圆锥、立方体等根据指定的一些参数可以得到对应的顶点坐标
| 球 | 柱 |
|---|---|
 |
 |
MeshData CreateBox(float width, float height, float depth, uint32 numSubdivisions);
MeshData CreateSphere(float radius, uint32 sliceCount, uint32 stackCount);
MeshData CreateGeosphere(float radius, uint32 numSubdivisions);
MeshData CreateCylinder(float bottomRadius, float topRadius, float height, uint32 sliceCount, uint32 stackCount);
MeshData CreateGrid(float width, float depth, uint32 m, uint32 n);
MeshData CreateQuad(float x, float y, float w, float h, float depth);
返回顶点数据结构体
struct MeshData
{
std::vector<Vertex> Vertices; // 顶点数组
std::vector<uint32> Indices32; // 顶点索引数组
std::vector<uint16>& GetIndices16()
{
if(mIndices16.empty())
{
mIndices16.resize(Indices32.size());
for(size_t i = 0; i < Indices32.size(); ++i)
mIndices16[i] = static_cast<uint16>(Indices32[i]);
}
return mIndices16;
}
private:
std::vector<uint16> mIndices16;
};
细探根签名
根签名是由一系列根参数定义而成,根参数有三种
- 描述符表(descriptor table):描述符堆的一窥啊连续范围,用于确定要绑定的资源
- 根描述符(root descriptor),又称内敛描述符(inline descriptor):通过直接设置根描述符即可指示要绑定的资源,而且无需将它存于描述符堆中。只有 CBV、SRV、UAV 可以绑定,纹理的 SRV 不行
- 根常量(root constant):可直接绑定一系列 32 位的常量值
由于性能问题,可放入一个根签名的数据以 64 DWORD 为限
- 描述符表:每个描述符表占用 1 DWORD
- 根描述符:每个根描述符占用 2 DWORD
- 根常量:每个常量 32 位,占用 1 DWORD
可以创建出任意组合的根签名,只要不超过 64 DWORD 上限即可
如果将 世界-视图-投影 矩阵存储到根常量中,会一次性用到 16 个 跟常量,占总的 1/4。所以由于程序的复杂性,常量缓冲区中的数据也将越来越大,因此不太可能仅使用根常量,而是三种根参数混用
代码中使用 CD3DX12_ROOT_PARAMETER 结构体数组来构建根参数,该结构体是对 D3D12_ROOT_PARAMETER 的扩展,并增加了一些辅助初始化函数
typedef struct D3D12_ROOT_PARAMETER
{
D3D12_ROOT_PARAMETER_TYPE ParameterType;
union
{
D3D12_ROOT_DESCRIPTOR_TABLE DescriptorTable;
D3D12_ROOT_CONSTANTS Constants;
D3D12_ROOT_DESCRIPTOR Descriptor;
} ;
D3D12_SHADER_VISIBILITY ShaderVisibility;
} D3D12_ROOT_PARAMETER;·
ParameterType定义根参数的类型(描述符表、根常量、CBV 根描述符、SRV 根描述符、 UAV 根描述符)DescriptorTable、Constants、Descriptor描述根参数的结构体ShaderVisibility在着色器程序中的可见性。如果某种资源只在像素着色器中使用,可以定义为D3D12_SHADER_VISIBILITY_PIXEL
那么什么是 DescriptorTable 描述符表呢?
typedef struct D3D12_ROOT_DESCRIPTOR_TABLE
{
UINT NumDescriptorRanges;
_Field_size_full_(NumDescriptorRanges) const D3D12_DESCRIPTOR_RANGE *pDescriptorRanges;
} D3D12_ROOT_DESCRIPTOR_TABLE;
通过 D3D12_ROOT_DESCRIPTOR_TABLE 存储一个 D3D12_DESCRIPTOR_RANGE 数组
typedef struct D3D12_DESCRIPTOR_RANGE
{
D3D12_DESCRIPTOR_RANGE_TYPE RangeType; // 描述符类型 SRV、UAV、CBA、采样器
UINT NumDescriptors; // 范围内描述符的数量
UINT BaseShaderRegister; // 此描述符将要绑定到的基准着色器寄存器
UINT RegisterSpace; // 能够在不同的寄存器空间中指定着色器寄存器
UINT OffsetInDescriptorsFromTableStart; // 描述符范围距离描述符表起始地址的偏移量
} D3D12_DESCRIPTOR_RANGE;
对于 BaseShaderRegister 可以这么理解,如果 NumDescriptors 值位 3,BaseShaderRegister 值为1,RangeType 为 CBV,那么会将数据存储到 b1、b2、b3 三个寄存器中,起始寄存器是 b1
如果
BaseShaderRegister值为 0,那么起始寄存器为b0,最后数据会存储到b0、b31、b2三个寄存器中
对于 RegisterSpace 默认值为0,表示使用 space0 空间。遂于资源数组来说,使用多重寄存器空间会更加方便
Texture2D gDiffuseMap : register(t0, space0)
Texture2D gNormalMap : register(t0, space1)
gDiffuseMap和gNormalMap都使用t0寄存器,但是各自存在不同空间中space0与space1
对于 OffsetInDescriptorsFromTableStart 可以这么理解,如果将 2 个 CBV、3 个 SRV 和 1 个 UAV 共6个描述符按顺序混合放置在一个描述符表中
CD3DX12_DESCRIPTOR_RANGE descRange[3];
descRange[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 2, 0, 0, 0);
descRange[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 3, 0, 0, 2);
descRange[2].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0, 0, 5);
可见看到 0,2,5 分别就是起始地址偏移
虽然 CBV 、SRV、UAV 的 BaseShaderRegister 都是 0,但是存储数据并不会冲突,因为类型不同,存储的寄存器也不同
另外 OffsetInDescriptorsFromTableStart 可以指定为 D3D12_DESCRIPTOR_RANGE_OFFSET_APPEND 来让 D3D 根据表中前一个描述符范围中描述符的数量来计算偏移,同时这个值也是 Init 函数 OffsetInDescriptorsFromTableStart 参数的默认值
那么什么是 Descriptor 根描述符呢?
typedef struct D3D12_ROOT_DESCRIPTOR
{
UINT ShaderRegister; // 要绑定的着色器,如果为 2 并且根参数是 CBV,则绑定到 b2 寄存器
UINT RegisterSpace; // 寄存器空间,与 D3D12_DESCRIPTOR_RANGE 中的 RegisterSpace 含义相同
} D3D12_ROOT_DESCRIPTOR;
使用根描述符可以简单直接的绑定资源的虚拟地址
D3D12_GPU_VIRTUAL_ADDRESS objCBAddress = objectCB->GetGPUVirtualAddress();
cmdList->SetGraphicRootConstantBufferView(0, objCBAddress);
SetGraphicRootConstantBufferView第一个参数 0 表示根参数的说因,即当前根描述符绑定到此编号的寄存器槽位
那么什么是 Constants 根常量呢?
typedef struct D3D12_ROOT_CONSTANTS
{
UINT ShaderRegister;
UINT RegisterSpace;
UINT Num32BitValues; // 此值为根参数所需的 32 位常量的个数
} D3D12_ROOT_CONSTANTS;
CD3DX12_ROOT_PARAMETER slotRootParameter[1];
slotRootParameter[0].InitAsConstants(2, 0); // 表示 2 个根常量,如果要 12 个就填写 12
CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(1, slotRootParameter, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT)
int size = 10;
float radius = 10.0f;
cmdList->SetGraphicsRoot32BitConstants(0, 1, &size, 0);
cmdList->SetGraphicsRoot32BitConstants(0, 1, &radius, 1);
对应的着色器代码
cbuffer cbSettings : register(b0) {
int gSize; // 对应 size
float w1; // 对应 radius
}
纹理贴图
2D 纹理是一种特定数据元素所构成的矩阵,它的用处之一是存储 2D 图像数据,纹理中的每个元素都存储着对应像素的颜色。但是这不是唯一的用途,比如法线贴图每个纹理元素都存储的是一个 3D 向量而非颜色数据
1D(D3D12_RESOURCE_DIMENSION_TEXTURE1D) 与 3D(D3D12_RESOURCE_DIMENSION_TEXTURE3D) 纹理就像由数据元素构成的 1D、3D 数组
1D、2D 和 3D 纹理实则都是用泛型接口 ID3D12Resource 来表示
纹理不同于缓冲区资源,因为缓冲区资源仅存储数据数组,纹理却可以有多个 mipmap 层级, GPU 会根据这个层级进行相应的特殊操作
| 格式示例 | 含义 |
|---|---|
| DXGI_FORMAT_R32G32B32_FLOAT | 表示元素由 3 个 32 位浮点构成 |
| DXGI_FORMAT_R16G16B16A16_UNORM | 表示元素由 4 个 16 位分量组成,映射到 [0, 1] 之间 |
| DXGI_FORMAT_R32G32_UINT | 元素由 2 个 32 位无符号构成 |
| DXGI_FORMAT_R8G8B8A8_UNORM | 元素由 4 个 8 位无符号分量构成,每个分量映射到范围 [0, 1] 之间 |
| DXGI_FORMAT_R8G8B8A8_SNORM | 元素由 4 个 8 位无符号分量构成,每个分量映射到范围 [-1, 1] 之间 |
| DXGI_FORMAT_R8G8B8A8_SINT | 元素由 4 个 8 位无符号分量构成,每个分量映射到范围 [-128, 127] 之间 |
| DXGI_FORMAT_R8G8B8A8_UINT | 元素由 4 个 8 位无符号分量构成,每个分量映射到范围 [0, 255] 之间 |
一个纹理可以绑定到渲染流水线的不同阶段,一个常见的例子是既可以将一纹理用作渲染目标,也可以把它作为着色器资源
纹理不能同时身兼数职,将数据渲染到一个纹理之后,再用它作为着色器资源,这种方法称为渲染到纹理(render-to-texture)
要使纹理扮演渲染目标与着色器资源这两种角色,就需要为此纹理资源创建两个描述符:一个存于渲染目标堆中(D3D12_DESCRIPTOR_HEAP_TYPE_RTV),一个位于着色器资源堆中(D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV)