
现代C++.md 5.6 KB
现代 C++
基于对象基础
一个类基本包括数据成员(字段) + 函数成员
class Point {
int x;
int y;
static int xx;
void Process() {
// do something
Process2(100);
}
void Process2(int x) {
// do something
}
static void Process3() {
xx++;
}
};
int Point::x = 0;
int main() {
Point pt;
pt.Process();
}
对于编译器来说,它可以这么理解上述代码
struct Point {
int x;
int y;
static int xx;
}
int Point::xx = 0;
void Process(Point* this) {
// do something
this->Process2(100);
}
void Process2(Point* this, int x) {
// do something
}
void Process3() {
Point::xx++;
}
将所有的成员函数都定义为,上述这种普通函数,然后给每个函数额外添加一个 Point* 的参数,用于指向执行该函数的对象
因为 Process3 是一个 static 函数,所以无法访问非 static 的成员属性,这个时候 Process3 就不用添加 Point*
相对来说,使用 C++ 的定义 class 的方法编写代码,可以将行为(函数)和状态(属性)结合起来进行编写
内存对齐
对于下面两个类的定义,虽然属性相同,但是对象内存大小占用却不相同
#pragma pack(8)
class P1 {
char a1;
int x;
char a2;
};
class P2 {
char a1;
char a2;
int x;
};
// sizeof(P1) 12
// sizeof(P2) 8
在 C++ 中存在内存对齐,使用内存对齐可以优化 CPU 存储数据效率、避免数据截断。对按对齐系数(4、8字节)整倍数进行对齐
可以使用
#pragma pack(4)控制对齐大小
- 内存对齐规则
- 成员对齐:每个成员的地址必须是其自身大小或
#pragma pack(n)设置值的较小值的倍数 - 结构体总大小:必须是所有成员中最大对齐值的整数倍
- 填充字节:编译器在成员之间插入空隙(padding),以满足对齐要求
- 成员对齐:每个成员的地址必须是其自身大小或
对于 class P1 来说
- char a1
- 大小:1 字节
- 对齐要求:min(1, 8) = 1
- 地址范围:0
- int x
- 大小:4 字节
- 对齐要求:min(4, 8) = 4
- 起始地址必须是 4 的倍数
- 当前地址是 1,需填充 3 字节(地址 1-3),使 x 从地址 4 开始
- 地址范围:4-7
- char a2
- 大小:1 字节
- 对齐要求:1
- 直接放在 x 后面,地址 8
当前总大小:0-8(共 9 字节)。结构体总大小必须是最大对齐值(4)的整数倍。9 向上取整到最近的 4 的倍数是 12,因此末尾填充 3 字节
最大对齐值:最大对齐值是结构体中所有成员的对齐值中的最大值,成员的对齐值 =
min(成员自身大小, #pragma pack(n) 设置的值)
最终内存布局
| a1 (1) | padding (3) | x (4) | a2 (1) | padding (3) |
对于 class P2 来说
- char a1
- 地址范围:0
- char a2
- 地址范围:1
- int x
- 对齐要求:4
- 当前地址是 2,需填充 2 字节(地址 2-3),使 x 从地址 4 开始
- 地址范围:4-7
当前总大小:0-7(共 8 字节)。8 已经是最大对齐值(4)的整数倍,无需额外填充
最终内存布局
| a1 (1) | a2 (1) | padding (2) | x (4) |
通过对比 P1 和 P2 的内存,可以得到结论:大内存属性放前面,小内存属性放后面
那么,如果在类中添加一个函数,会影响这个对象大小吗?
class Point {
int x;
int y;
void Process() {}
};
// sizeof(Point) 8
通过上面的代码可以发现,sizeof(Point) 的大小还是 8,函数定义并没有增加 Point 的大小
这是因为前面解释过编译器如何理解 C++ 对象的,就是一个数据结构体 + 全局函数
也就是说,Point 对象被解析成了下面这样, Process 被解析成了全局函数,占用的是代码段大小,不影响对象大小
struct Point { int x; int y;};
Process(Point* this)
{
// do something
}
但是,如果是下面定义的对象,又不一样,Point1 对象有一个虚函数 Process2,需要一个指针指向虚函数表,所以 Point1 额外需要一个虚函数指针,因此 sizeof(Point1) 大小是 16
指针的大小根据平台不同,可能是 4,也可能是 8
class Point1 {
int x;
int y;
void Process() {}
virtual void Process2() {}
};
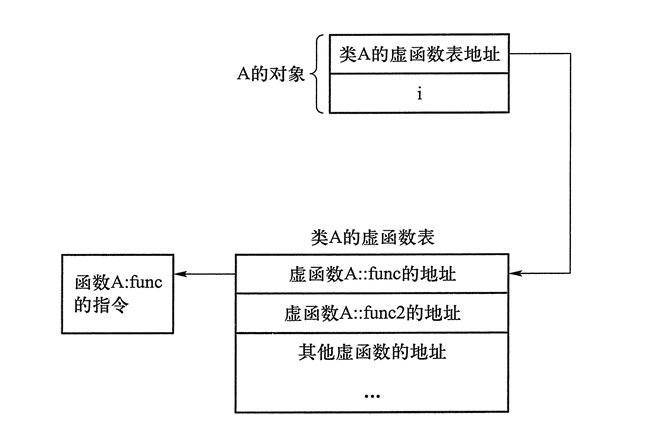
以上图为例,如果一个类有虚函数,那么这个类对象在内存中第一个属性是一个指针,指向这个类的虚函数表
既然知道这个类的第一个属性是一个指针,是否可以通过指针获取到虚函数表,然后获取虚函数表的第一个函数并执行它呢?
#include <iostream>
using namespace std;
class Point1 {
int x;
int y;
virtual void Process2(int InParam) { std::cout << "hello world " << InParam << std::endl; }
};
typedef void(*Fun)(Point1*, int);
int main()
{
auto a = new Point1();
std::cout << sizeof(int) << " " << sizeof(long) << " " << sizeof(void*) << std::endl;
Fun pfun = (Fun)*((long *)*(long *)(a));
pfun(a, 4);
delete a;
return 0;
}
这里使用
long*而不是int*是因为我机器上指针大小是 8 与long的大小相同
通过 *(long *)a 将对象 a 从 Point* 强转成 long*,然后对其取地址,得到虚函数表的首地址
将虚函数表的首地址强转成 long* 并对其取地址,得到第一个虚函数的指针,再将其强转成 void *(int) 的函数指针,就可以执行它
为什么要定义
Fun为void(*)(Point*, int),还记得之前说过编译器如何对 C++ 类的函数做处理的吗?