|
|
@@ -259,4 +259,228 @@ Alignment = FMath::Max<uint32>(Alignment, Private::DEFAULT_BINNED_ALLOCATOR_ALIG
|
|
|
|
|
|
> `Size` 不可能为 0,试想如何申请不存在的东西呢?指针如何指向不存在的对象呢?
|
|
|
|
|
|
+接下来就是通过 `Size` 获取对应的 `FTableTool`
|
|
|
+
|
|
|
+根据情况,调用 `Private::AllocatePoolMemory` 给 Pool 分配内存空间,通过 `Private::AllocateBlockFromPool` 申请对象的内存空间
|
|
|
+
|
|
|
+```cpp
|
|
|
+FPoolTable* Table = MemSizeToPoolTable[Size];
|
|
|
+#ifdef USE_FINE_GRAIN_LOCKS
|
|
|
+FScopeLock TableLock(&Table->CriticalSection);
|
|
|
+#endif
|
|
|
+Private::TrackStats(Table, (uint32)Size);
|
|
|
+FPoolInfo* Pool = Table->FirstPool;
|
|
|
+if( !Pool )
|
|
|
+{
|
|
|
+ Pool = Private::AllocatePoolMemory(*this, Table, Private::BINNED_ALLOC_POOL_SIZE/*PageSize*/, Size);
|
|
|
+}
|
|
|
+
|
|
|
+Free = Private::AllocateBlockFromPool(*this, Table, Pool, Alignment);
|
|
|
+```
|
|
|
+
|
|
|
+### Private
|
|
|
+
|
|
|
+```cpp
|
|
|
+class FMallocBinned : public FMalloc
|
|
|
+{
|
|
|
+ struct Private;
|
|
|
+ // ....
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+可能有人纳闷,这是个什么写法?
|
|
|
+
|
|
|
+其实这里声明了一个名为 `Private` 的结构体,在 `.h` 文件中,真正的实现是在 `.cpp` 文件中
|
|
|
+
|
|
|
+这就是名为 `PImlp` 模式,`PImpl`通过一个私有的成员指针,将指针指向的类的内部实现全部隐藏
|
|
|
+
|
|
|
+```cpp
|
|
|
+struct FMallocBinned::Private
|
|
|
+{
|
|
|
+ // ....
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+- 这种方法隐藏了大量实现。即使在类中将某些成员限定为 `private`,外界仍旧可以通过对应的 `setter/getter` 接口猜测到类的内部实现。如果使用`PImpl`,则只需要提供 `public` 接口即可
|
|
|
+- 修改 `PImpl` 不会影响类A本身,且修改发生在 `.cpp` 文件中。指针的大小是确定的,因此,发生修改是,头文件不会发生变化。这种方法可以降低编译依赖,提高编译速度
|
|
|
+
|
|
|
+比如,如果对外封装 SDK,外界能拿到 `DLL` 和 `.h` 文件,使用 `PImpl` 模式可以在 `.h` 文件中完全隐藏属性定义和大部分函数定义,只留下对外用的接口函数
|
|
|
+
|
|
|
+#### GetPoolInfo
|
|
|
+
|
|
|
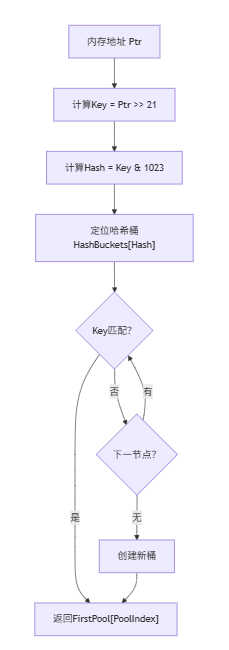
+函数的作用是如何通过一个指针,判定其所属的 `FPoolInfo`
|
|
|
+
|
|
|
+```cpp
|
|
|
+static FORCEINLINE FPoolInfo* GetPoolInfo(FMallocBinned& Allocator, UPTRINT Ptr)
|
|
|
+```
|
|
|
+
|
|
|
+所谓的 `UPTRINT` 其实是为了表示一个地址的大小,64位还是32位,通过模板匹配 `sizeof(void*)` 的值,进而得到 `uint32` 或者 `uint64`
|
|
|
+
|
|
|
+```cpp
|
|
|
+typedef SelectIntPointerType<uint32, uint64, sizeof(void*)>::TIntPointer UPTRINT;
|
|
|
+```
|
|
|
+
|
|
|
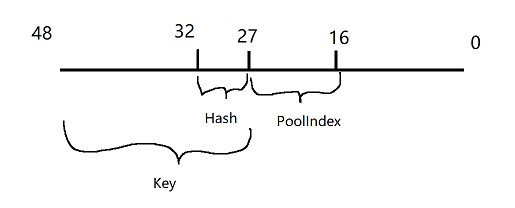
+64 位内存地址实际用到 48 位,32 位系统实际用到 32 位
|
|
|
+
|
|
|
+```cpp
|
|
|
+UPTRINT Key = Ptr >> Allocator.HashKeyShift;
|
|
|
+UPTRINT Hash = Key & (Allocator.MaxHashBuckets - 1);
|
|
|
+UPTRINT PoolIndex = ((UPTRINT)Ptr >> Allocator.PoolBitShift) & Allocator.PoolMask;
|
|
|
+```
|
|
|
+
|
|
|
+> HashKeyShift = PoolBitShift + IndirectPoolBitShift
|
|
|
+
|
|
|
+> `IndirectPoolBitShift` 是 每页能存储的 `FPoolInfo` 数量 的对数,比如 64KB 的页能存储 2048 个 `FPoolInfo`,得到的 `IndirectPoolBitShift` 就是 11
|
|
|
+
|
|
|
+> PoolMask = ( ( 1ull << ( HashKeyShift - PoolBitShift ) ) - 1 )
|
|
|
+
|
|
|
+假设 `HashKeyShift` 是 27,`MaxHashBuckets` 是 32,`PoolBitShift` 是 16,`PoolMask` 是 11 位
|
|
|
+
|
|
|
+那么 64 位系统下,有效位数是 48 位,右移 27 位,得到高位 21 位作为 `Key`
|
|
|
+
|
|
|
+通过 `MaxHashBuckets` 取 `Key` 的低 5 位,得到 `Hash`
|
|
|
+
|
|
|
+通过右移 16 后对取低位 11 位作为 `PoolIndex`
|
|
|
+
|
|
|
+综上所述,对于一个 64位系统的指针,有效位数是 48 位,对一个指针将其划分成三部分
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+- `Hash` 有 5 位二进制,取值是 0 ~ 31
|
|
|
+- `PoolIndex` 有 11 位二进制,取值是 0 ~ 2047
|
|
|
+
|
|
|
+```cpp
|
|
|
+PoolHashBucket* Collision = &Allocator.HashBuckets[Hash];
|
|
|
+do
|
|
|
+{
|
|
|
+ if (Collision->Key == Key || !Collision->FirstPool)
|
|
|
+ {
|
|
|
+ if (!Collision->FirstPool)
|
|
|
+ {
|
|
|
+ Collision->Key = Key;
|
|
|
+ InitializeHashBucket(Allocator, Collision);
|
|
|
+ CA_ASSUME(Collision->FirstPool);
|
|
|
+ }
|
|
|
+ return &Collision->FirstPool[PoolIndex];
|
|
|
+ }
|
|
|
+
|
|
|
+ Collision = Collision->Next;
|
|
|
+} while (Collision != &Allocator.HashBuckets[Hash]);
|
|
|
+```
|
|
|
+
|
|
|
+> `InitializeHashBucket` 函数中会创建 `FirstPool` 对应的 `FPoolInfo` 数组,其长度为 `IndirectPoolBlockSize`
|
|
|
+
|
|
|
+通过上述代码,以及前面定义的变量取值范围
|
|
|
+
|
|
|
+不难发现 `Allocator.HashBuckets` 是一个长度为 32 的数组,`Collision->FirstPool` 是一个长度为 2048 的数组
|
|
|
+
|
|
|
+1. 通过 `Hash` 值进行一级查找,快速定位到所属的 `HashBuckets`
|
|
|
+2. 通过 `Key` 在链表中进行二级查找
|
|
|
+3. 通过 `PoolIndex` 直接得到所属的 `FPageInfo`
|
|
|
+
|
|
|
+注意这里的 `while (Collision != &Allocator.HashBuckets[Hash])` 终止循环条件是 等于链表头,这是因为 `PoolHashBucket` 是循环链表
|
|
|
+
|
|
|
+从链表的插入逻辑即可窥探,`Link` 函数即为插入链表的逻辑,可以发现插入节点是向当前节点的前面插入
|
|
|
+
|
|
|
+> 虽然函数参数是 `After`
|
|
|
+
|
|
|
+```cpp
|
|
|
+void Link( PoolHashBucket* After )
|
|
|
+{
|
|
|
+ Link(After, Prev, this);
|
|
|
+}
|
|
|
+
|
|
|
+static void Link( PoolHashBucket* Node, PoolHashBucket* Before, PoolHashBucket* After )
|
|
|
+{
|
|
|
+ Node->Prev=Before;
|
|
|
+ Node->Next=After;
|
|
|
+ Before->Next=Node;
|
|
|
+ After->Prev=Node;
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+另外,注意循环中的条件判断 `!Collision->FirstPool`,这里表示 `PoolHashBucket` 虽然被创建了,但是并没有被使用,于是乎直接修改其 `Key`,重新启用
|
|
|
+
|
|
|
+当没有找到对应的 `PoolHashBucket` 时,则创建一个新的,并插入到 `HashBuckets` 数组中
|
|
|
+
|
|
|
+```cpp
|
|
|
+PoolHashBucket* NewBucket = CreateHashBucket(Allocator);
|
|
|
+NewBucket->Key = Key;
|
|
|
+Allocator.HashBuckets[Hash].Link(NewBucket);
|
|
|
+```
|
|
|
+
|
|
|
+虽然当 `Hash` 值冲突时,通过 `PoolHashBucket` 链表进行逐个查找。但是游戏分配通常集中特定区域,冲突率较低,比较少见出现 `O(n)` 的情况
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+通过前面的一系列定位,可以得到一个 `FPoolInfo`,用于管理一个内存页的大小,这个内存页刚好是 64 KB,也就是 0~15 能表示的内容
|
|
|
+
|
|
|
+#### AllocatePoolMemory
|
|
|
+
|
|
|
+用于创建 `FPoolInfo` 对象
|
|
|
+
|
|
|
+首先先申请一块 `PageSize` 倍数的内存
|
|
|
+
|
|
|
+`Align` 就是经典的内存对齐算法,得到的值是
|
|
|
+
|
|
|
+1. 大于等于 `Bytes`
|
|
|
+2. 是 `PageSize` 倍数
|
|
|
+3. 同时满足上述条件的最小值
|
|
|
+
|
|
|
+```cpp
|
|
|
+uint32 Blocks = PoolSize / Table->BlockSize;
|
|
|
+uint32 Bytes = Blocks * Table->BlockSize;
|
|
|
+UPTRINT OsBytes = Align(Bytes, PageSize);
|
|
|
+
|
|
|
+FFreeMem* Free = (FFreeMem*)OSAlloc(Allocator, OsBytes, ActualPoolSize);
|
|
|
+```
|
|
|
+
|
|
|
+> 代码有些修改,大差不差
|
|
|
+
|
|
|
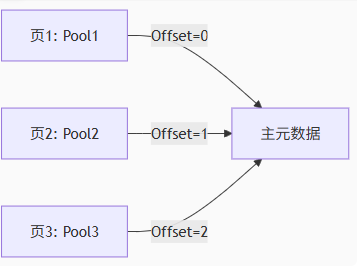
+通过前面的 `GetPoolInfo`,通过申请的地址,创建或者获得对应的 `FPoolInfo`,如果一次性申请几个页的大小,设置对应的 `PoolInfo` 的 `TableIndex` 为 `Offset` 序号索引,`AllocSize` 和 `FreeMem` 为空
|
|
|
+
|
|
|
+```cpp
|
|
|
+FPoolInfo* Pool;
|
|
|
+{
|
|
|
+#ifdef USE_FINE_GRAIN_LOCKS
|
|
|
+ FScopeLock PoolInfoLock(&Allocator.AccessGuard);
|
|
|
+#endif
|
|
|
+ Pool = GetPoolInfo(Allocator, (UPTRINT)Free);
|
|
|
+ for (UPTRINT i = (UPTRINT)PageSize, Offset = 0; i < OsBytes; i += PageSize, ++Offset)
|
|
|
+ {
|
|
|
+ FPoolInfo* TrailingPool = GetPoolInfo(Allocator, ((UPTRINT)Free) + i);
|
|
|
+ check(TrailingPool);
|
|
|
+
|
|
|
+ //Set trailing pools to point back to first pool
|
|
|
+ TrailingPool->SetAllocationSizes(0, 0, (uint32)Offset, (uint32)Allocator.BinnedOSTableIndex);
|
|
|
+ }
|
|
|
+
|
|
|
+
|
|
|
+ BINNED_PEAK_STATCOUNTER(Allocator.OsPeak, BINNED_ADD_STATCOUNTER(Allocator.OsCurrent, OsBytes));
|
|
|
+ BINNED_PEAK_STATCOUNTER(Allocator.WastePeak, BINNED_ADD_STATCOUNTER(Allocator.WasteCurrent, (OsBytes - Bytes)));
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+最后对第一个 `PoolInfo` 进行设置
|
|
|
+
|
|
|
+```cpp
|
|
|
+Pool->Link( Table->FirstPool ); // 插入池链表头部
|
|
|
+Pool->SetAllocationSizes(Bytes, OsBytes, TableIndex, Allocator.BinnedOSTableIndex);
|
|
|
+Pool->Taken = 0;
|
|
|
+Pool->FirstMem = Free; // 指向申请的内存
|
|
|
+#if STATS
|
|
|
+Table->NumActivePools++;
|
|
|
+Table->MaxActivePools = FMath::Max(Table->MaxActivePools, Table->NumActivePools);
|
|
|
+#endif
|
|
|
+// Create first free item.
|
|
|
+Free->NumFreeBlocks = Blocks; // 包含的页表数量
|
|
|
+Free->Next = nullptr;
|
|
|
+```
|
|
|
+
|
|
|
+> `NumFreeBlocks` 表示申请的页表个数
|
|
|
+
|
|
|
+#### AllocateBlockFromPool
|
|
|
+
|
|
|
|

 NiceTry12138
NiceTry12138
{kind=link}
{kind=link}
{kind=link}