|
|
@@ -0,0 +1,544 @@
|
|
|
+# FName
|
|
|
+
|
|
|
+> 参考文章 https://zhuanlan.zhihu.com/p/500887262
|
|
|
+
|
|
|
+## 预定义全局变量
|
|
|
+
|
|
|
+首先定义一些全局变量
|
|
|
+
|
|
|
+```cpp
|
|
|
+enum {NAME_SIZE = 1024};
|
|
|
+
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+constexpr uint32 FNamePoolShardBits = 10;
|
|
|
+#else
|
|
|
+constexpr uint32 FNamePoolShardBits = 8;
|
|
|
+#endif
|
|
|
+
|
|
|
+constexpr uint32 FNamePoolShards = 1 << FNamePoolShardBits;
|
|
|
+constexpr uint32 FNamePoolInitialSlotBits = 8;
|
|
|
+constexpr uint32 FNamePoolInitialSlotsPerShard = 1 << FNamePoolInitialSlotBits;
|
|
|
+
|
|
|
+static constexpr uint32 FNameMaxBlockBits = 13; // Limit block array a bit, still allowing 8k * block size = 1GB - 2G of FName entry data
|
|
|
+static constexpr uint32 FNameBlockOffsetBits = 16;
|
|
|
+static constexpr uint32 FNameMaxBlocks = 1 << FNameMaxBlockBits;
|
|
|
+static constexpr uint32 FNameBlockOffsets = 1 << FNameBlockOffsetBits;
|
|
|
+static constexpr uint32 FNameEntryIdBits = FNameBlockOffsetBits + FNameMaxBlockBits;
|
|
|
+static constexpr uint32 FNameEntryIdMask = (1 << FNameEntryIdBits ) - 1;
|
|
|
+
|
|
|
+static constexpr uint32 EntryIdBits = FNameMaxBlockBits + FNameBlockOffsetBits;
|
|
|
+static constexpr uint32 EntryIdMask = (1 << EntryIdBits) - 1;
|
|
|
+static constexpr uint32 ProbeHashShift = EntryIdBits;
|
|
|
+static constexpr uint32 ProbeHashMask = ~EntryIdMask;
|
|
|
+```
|
|
|
+
|
|
|
+| 常量名 | 值 | 作用说明 |
|
|
|
+| --- | --- | --- |
|
|
|
+| NAME_SIZE | 1024 | 名称字符串的最大长度(字符数) |
|
|
|
+| FNamePoolShardBits | 10(保留大小写时)8(不保留时) | 名称池分片数的位宽 |
|
|
|
+| FNamePoolShards | 1024(保留大小写时)56(不保留时) | 名称池的分片总数 |
|
|
|
+| FNamePoolInitialSlotBits | 8 | 初始槽位数的位宽 |
|
|
|
+| FNamePoolInitialSlotsPerShard | 256 | 每个分片的初始槽位数 |
|
|
|
+| FNameMaxBlockBits | 13 | 内存块索引的最大位宽 |
|
|
|
+| FNameBlockOffsetBits | 16 | 块内偏移量的位宽 |
|
|
|
+| FNameMaxBlocks | 8 ,192 | 最大内存块数 |
|
|
|
+| FNameBlockOffsets | 65 ,536 | 每个内存块的最大条目数 |
|
|
|
+| FNameEntryIdBits | 29 | 名称条目ID的总位宽 |
|
|
|
+| FNameEntryIdMask | 0x1FFFFFFF | 名称条目ID的位掩码 |
|
|
|
+| EntryIdBits | 29 | 条目ID位宽(重复定义) |
|
|
|
+| EntryIdMask | 0x1FFFFFFF | 条目ID位掩码(重复定义) |
|
|
|
+| ProbeHashShift | 29 | 探测哈希的移位值 |
|
|
|
+| ProbeHashMask | 0xE0000000 | 探测哈希的位掩码 |
|
|
|
+
|
|
|
+## 基本数据结构
|
|
|
+
|
|
|
+### FNameStringView
|
|
|
+
|
|
|
+```cpp
|
|
|
+struct FNameStringView
|
|
|
+{
|
|
|
+ // functions ...
|
|
|
+
|
|
|
+ union
|
|
|
+ {
|
|
|
+ const void* Data;
|
|
|
+ const ANSICHAR* Ansi;
|
|
|
+ const WIDECHAR* Wide;
|
|
|
+ };
|
|
|
+
|
|
|
+ uint32 Len;
|
|
|
+ bool bIsWide;
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+可以看到 `FNameStringView` 内容很简单,一个用于存储数据的 `union`,一个用于存储长度的 `len`,一个用于判断是否是宽字符 的 `bool` 值
|
|
|
+
|
|
|
+### FNameHash
|
|
|
+
|
|
|
+`FNameHash` 中会计算很多**数值**,用于后续的判断流程
|
|
|
+
|
|
|
+```cpp
|
|
|
+struct FNameHash
|
|
|
+{
|
|
|
+ // else functions
|
|
|
+
|
|
|
+ uint32 ShardIndex;
|
|
|
+ uint32 UnmaskedSlotIndex; // Determines at what slot index to start probing
|
|
|
+ uint32 SlotProbeHash; // Helps cull equality checks (decode + strnicmp) when probing slots
|
|
|
+ FNameEntryHeader EntryProbeHeader; // Helps cull equality checks when probing inspects entries
|
|
|
+
|
|
|
+ static constexpr uint64 AlgorithmId = 0xC1640000;
|
|
|
+ static constexpr uint32 ShardMask = FNamePoolShards - 1;
|
|
|
+ template<class CharType>
|
|
|
+
|
|
|
+ FNameHash(const CharType* Str, int32 Len)
|
|
|
+ : FNameHash(GenerateHash(Str, Len), Len, (bool)IsAnsiNone(Str, Len), sizeof(CharType) == sizeof(WIDECHAR))
|
|
|
+ {}
|
|
|
+
|
|
|
+ FNameHash(uint64 Hash, int32 Len, bool IsNone, bool bIsWide)
|
|
|
+ {
|
|
|
+ uint32 Hi = static_cast<uint32>(Hash >> 32);
|
|
|
+ uint32 Lo = static_cast<uint32>(Hash);
|
|
|
+
|
|
|
+ // "None" has FNameEntryId with a value of zero
|
|
|
+ // Always set a bit in SlotProbeHash for "None" to distinguish unused slot values from None
|
|
|
+ // @see FNameSlot::Used()
|
|
|
+ uint32 IsNoneBit = IsNone << FNameSlot::ProbeHashShift;
|
|
|
+
|
|
|
+ static_assert((ShardMask & FNameSlot::ProbeHashMask) == 0, "Masks overlap");
|
|
|
+
|
|
|
+ ShardIndex = Hi & ShardMask;
|
|
|
+ UnmaskedSlotIndex = Lo;
|
|
|
+ SlotProbeHash = (Hi & FNameSlot::ProbeHashMask) | IsNoneBit;
|
|
|
+ EntryProbeHeader.Len = Len;
|
|
|
+ EntryProbeHeader.bIsWide = bIsWide;
|
|
|
+
|
|
|
+ // When we always use lowercase hashing, we can store parts of the hash in the entry
|
|
|
+ // to avoid copying and decoding entries needlessly. WITH_CUSTOM_NAME_ENCODING
|
|
|
+ // that makes this important is normally on when WITH_CASE_PRESERVING_NAME is off.
|
|
|
+#if !WITH_CASE_PRESERVING_NAME
|
|
|
+ static constexpr uint32 EntryProbeMask = (1u << FNameEntryHeader::ProbeHashBits) - 1;
|
|
|
+ EntryProbeHeader.LowercaseProbeHash = static_cast<uint16>((Hi >> FNamePoolShardBits) & EntryProbeMask);
|
|
|
+#endif
|
|
|
+ }
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+注意 `FNameHash(const CharType* Str, int32 Len)` 构造函数,通过 `GenerateHash(Str, Len)` 计算得到 `uint64` 的 `Hash` 值,这是一个 64 位的 `Hash` 值,使用的是 `CityHash64` 算法
|
|
|
+
|
|
|
+那么,最后执行的构造用于计算 `ShardIndex`、`SlotProbeHash` 等数值
|
|
|
+
|
|
|
+| 变量名 | 计算 | 作用 |
|
|
|
+| --- | --- | --- |
|
|
|
+| Hi | `Hash >> 32` | Hash 值的高 32 位 |
|
|
|
+| Lo | `Hash` | Hash 值的低 32 位 |
|
|
|
+| IsNoneBit | `(bool)IsAnsiNone(Str, Len)` | 对 `"None"` 的特殊处理 |
|
|
|
+| ShardIndex | `Hi & ShardMask` | `Hi` 的低 10 位 |
|
|
|
+| UnmaskSlotIndex | `Lo` | `Hash` 值的低 32 位 |
|
|
|
+| SlotProbeHash | `(Hi & FNameSlot::ProbeHashMask) \| IsNoneBit` | `Hi` 的高三位,用于快速匹配 |
|
|
|
+| EntryProbeHeader.Len | | 字符串长度 |
|
|
|
+| EntryProbeHeader.bIsWide | | 是否是宽字符串 |
|
|
|
+
|
|
|
+### FNameValue
|
|
|
+
|
|
|
+很简单的结构体,就是一个存储了 `Name` 和 `Hash` 的结构体,`Name` 是 `FNameStringView`,`Hash` 是 `FNameHash`
|
|
|
+```cpp
|
|
|
+template<ENameCase Sensitivity>
|
|
|
+struct FNameValue
|
|
|
+{
|
|
|
+ explicit FNameValue(FNameStringView InName)
|
|
|
+ : Name(InName)
|
|
|
+ , Hash(HashName<Sensitivity>(InName))
|
|
|
+ {}
|
|
|
+
|
|
|
+ FNameValue(FNameStringView InName, FNameHash InHash)
|
|
|
+ : Name(InName)
|
|
|
+ , Hash(InHash)
|
|
|
+ {}
|
|
|
+
|
|
|
+ FNameValue(FNameStringView InName, uint64 InHash)
|
|
|
+ : Name(InName)
|
|
|
+ , Hash(Name.bIsWide ? FNameHash(Name.Wide, Name.Len, InHash) : FNameHash(Name.Ansi, Name.Len, InHash))
|
|
|
+ {}
|
|
|
+
|
|
|
+ FNameStringView Name;
|
|
|
+ FNameHash Hash;
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+ FNameEntryId ComparisonId;
|
|
|
+#endif
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+### FNameSlot
|
|
|
+
|
|
|
+维护一个名为 `IdAndHash` 的 `uint32` 属性,该属性值存储存储着两个内存
|
|
|
+
|
|
|
+- 高 3 位:存储着 `Probe` 值,用于快速比较
|
|
|
+- 低 29 位:存储着 `ID` 值,存储着其他信息,可以创建 `FNameEntryId` 对象
|
|
|
+
|
|
|
+```cpp
|
|
|
+struct FNameSlot
|
|
|
+{
|
|
|
+public:
|
|
|
+ // else functions ...
|
|
|
+
|
|
|
+ FNameEntryId GetId() const { return FNameEntryId::FromUnstableInt(IdAndHash & EntryIdMask); }
|
|
|
+ uint32 GetProbeHash() const { return IdAndHash & ProbeHashMask; }
|
|
|
+private:
|
|
|
+ uint32 IdAndHash = 0;
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+### FNameEntryId
|
|
|
+
|
|
|
+存储值
|
|
|
+
|
|
|
+`FNameEntryId` 可以转换成 `FNameEntryHandle`
|
|
|
+
|
|
|
+```cpp
|
|
|
+/** Opaque id to a deduplicated name */
|
|
|
+struct FNameEntryId
|
|
|
+{
|
|
|
+ // some functions ...
|
|
|
+
|
|
|
+private:
|
|
|
+ uint32 Value;
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+### FNameEntryHandle
|
|
|
+
|
|
|
+存储着 `Block` 和 `Offset`
|
|
|
+
|
|
|
+- `Block` 区块索引
|
|
|
+- `Offset` 区块内偏移
|
|
|
+
|
|
|
+```cpp
|
|
|
+struct FNameEntryHandle
|
|
|
+{
|
|
|
+ uint32 Block = 0;
|
|
|
+ uint32 Offset = 0;
|
|
|
+
|
|
|
+ // some function else ...
|
|
|
+
|
|
|
+ operator FNameEntryId() const
|
|
|
+ {
|
|
|
+ return FNameEntryId::FromUnstableInt(Block << FNameBlockOffsetBits | Offset);
|
|
|
+ }
|
|
|
+
|
|
|
+ explicit operator bool() const { return Block | Offset; }
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+## 容器数据结构
|
|
|
+
|
|
|
+### FNamePoolShard
|
|
|
+
|
|
|
+`FNamePoolShard` 是一个管理 `FNameSlot` 数组的容器
|
|
|
+
|
|
|
+```cpp
|
|
|
+class FNamePoolShard : public FNamePoolShardBase
|
|
|
+{
|
|
|
+ // some functions ...
|
|
|
+}
|
|
|
+
|
|
|
+class alignas(PLATFORM_CACHE_LINE_SIZE) FNamePoolShardBase : FNoncopyable
|
|
|
+{
|
|
|
+ enum { LoadFactorQuotient = 9, LoadFactorDivisor = 10 }; // I.e. realloc slots when 90% full
|
|
|
+
|
|
|
+ mutable FRWLock Lock;
|
|
|
+ uint32 UsedSlots = 0;
|
|
|
+ uint32 CapacityMask = 0;
|
|
|
+ FNameSlot* Slots = nullptr;
|
|
|
+ FNameEntryAllocator* Entries = nullptr;
|
|
|
+ uint32 NumCreatedEntries = 0;
|
|
|
+ uint32 NumCreatedWideEntries = 0;
|
|
|
+ uint32 NumCreatedWithNumberEntries = 0;
|
|
|
+
|
|
|
+public:
|
|
|
+ void Initialize(FNameEntryAllocator& InEntries)
|
|
|
+ {
|
|
|
+ LLM_SCOPE(ELLMTag::FName);
|
|
|
+ Entries = &InEntries;
|
|
|
+
|
|
|
+ Slots = (FNameSlot*)FMemory::Malloc(FNamePoolInitialSlotsPerShard * sizeof(FNameSlot), alignof(FNameSlot));
|
|
|
+ memset(Slots, 0, FNamePoolInitialSlotsPerShard * sizeof(FNameSlot));
|
|
|
+ CapacityMask = FNamePoolInitialSlotsPerShard - 1;
|
|
|
+ }
|
|
|
+
|
|
|
+ // some functions ...
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+通过上述源码,可以发现
|
|
|
+
|
|
|
+- 有一个 `Slots` 数组,存储 `FNameSlot` 对象
|
|
|
+- 有一个 `FNameEntryAllocator` 用于创建 `FNameEntry` 的分配器
|
|
|
+- 有一个 `Lock` 作为锁,处理多线程的情况
|
|
|
+- 有一个 `CapacityMask` 作为容量的掩码,表示当前 `Slots` 数组的长度
|
|
|
+
|
|
|
+通过 `Initialize`
|
|
|
+
|
|
|
+1. 设置了 `FNameEntryAllocator` 内存分配器
|
|
|
+2. 预创建了 `FNamePoolInitialSlotsPerShard`(256) 个 `Slot`
|
|
|
+3. 设置 `CapacityMask` 容量掩码位 255,也就是位运算的后 8 位
|
|
|
+
|
|
|
+除了 `Initialize` 之外,还有 `Grow` 函数,用于扩充 `Slot` 数组长度,类似 `std::vector` 超过一定长度之后自动扩充 2 倍容量
|
|
|
+
|
|
|
+#### Probe
|
|
|
+
|
|
|
+```cpp
|
|
|
+FORCEINLINE FNameSlot& Probe(const FNameValue<Sensitivity>& Value) const
|
|
|
+{
|
|
|
+ return Probe(Value.Hash.UnmaskedSlotIndex,
|
|
|
+ [&](FNameSlot Slot) { return Slot.GetProbeHash() == Value.Hash.SlotProbeHash &&
|
|
|
+ EntryEqualsValue<Sensitivity>(Entries->Resolve(Slot.GetId()), Value); });
|
|
|
+}
|
|
|
+
|
|
|
+template<class PredicateFn>
|
|
|
+FORCEINLINE FNameSlot& Probe(uint32 UnmaskedSlotIndex, PredicateFn Predicate) const
|
|
|
+{
|
|
|
+ const uint32 Mask = CapacityMask;
|
|
|
+ for (uint32 I = FNameHash::GetProbeStart(UnmaskedSlotIndex, Mask); true; I = (I + 1) & Mask)
|
|
|
+ {
|
|
|
+ FNameSlot& Slot = Slots[I];
|
|
|
+ if (!Slot.Used() || Predicate(Slot))
|
|
|
+ {
|
|
|
+ return Slot;
|
|
|
+ }
|
|
|
+ }
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+`Probe` 用于查找可以使用的 `Slot`
|
|
|
+
|
|
|
+可以使用的定义
|
|
|
+
|
|
|
+1. 没有被使用过的 `Slot`
|
|
|
+2. 虽然被使用了,但是内容相同的 `Slot`
|
|
|
+
|
|
|
+结合上述的两个 `Probe` 函数
|
|
|
+
|
|
|
+第一个 `Probe` 像第二个 `Probe` 传入了 `UnmaskedSlotIndex` 和一个 `lambda` 表达式
|
|
|
+
|
|
|
+```cpp
|
|
|
+[&](FNameSlot Slot) {
|
|
|
+ return Slot.GetProbeHash() == Value.Hash.SlotProbeHash &&
|
|
|
+ EntryEqualsValue<Sensitivity>(Entries->Resolve(Slot.GetId()), Value);
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+查看 `lambda` 表达式的内容,首先对比 `ProbeHash` 值是否相等,位运算很快,所以可以高效的删除大部分 `ProbeHash` 值不相同的 `Slot`
|
|
|
+
|
|
|
+然后通过 `EntryEqualsValue` 进行更加详细,但是占用性能的比较,具体的跟代码进去看就行
|
|
|
+
|
|
|
+> 先比较 `FNameEntryHeader` 是否相同,如果相同再对 `Data` 的具体内容进行逐字符比较
|
|
|
+
|
|
|
+接下来,在第二个 `Probe` 进行具体的 `Slot` 查找
|
|
|
+
|
|
|
+注意,这里查找的起点是 `FNameHash::GetProbeStart(UnmaskedSlotIndex, CapacityMask)`
|
|
|
+
|
|
|
+起点是 `UnmaskedSlotIndex & CapacityMask`,也就是字符串 `Hash` 的低 32 位与 `CapacityMask` 求与,得到最后几位
|
|
|
+
|
|
|
+> 因为 `Slots` 的长度每次都是 2 的倍数,`CapacityMask` 刚好就是 **2的倍数-1**,也就刚好取到 `UnmaskedSlotIndex` 最后几位,并且刚好是 `Slots` 容器长度的范围内
|
|
|
+
|
|
|
+1. 一般情况下,`Slots` 是一个稀疏数组,如果每次从头开始遍历查找,性能消耗较大。所以从 `GetProbeStart` 作为起点开始向后查找,成功率高
|
|
|
+2. 如果是两个相同的 `FName`,通过 `GetProbeStart` 大概率可以得到相同的值,也能减少无用查找
|
|
|
+
|
|
|
+#### Insert
|
|
|
+
|
|
|
+```cpp
|
|
|
+template<class ScopeLock = FWriteScopeLock>
|
|
|
+FORCEINLINE FNameEntryId Insert(const FNameValue<Sensitivity>& Value, bool& bCreatedNewEntry)
|
|
|
+{
|
|
|
+ ScopeLock _(Lock);
|
|
|
+ FNameSlot& Slot = Probe(Value);
|
|
|
+
|
|
|
+ if (Slot.Used())
|
|
|
+ {
|
|
|
+ return Slot.GetId();
|
|
|
+ }
|
|
|
+
|
|
|
+ bCreatedNewEntry = true;
|
|
|
+ return CreateAndInsertEntry<ScopeLock>(Slot, Value);
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+通过 `Probe` 找到能供使用的 `Slot`
|
|
|
+
|
|
|
+- 如果 `Slot` 不为空则表示该 `FName` 已经被储存过了,直接返回现有值即可
|
|
|
+- 如果 `Slot` 为空,则使用 `CreateAndInsertEntry` 设置 `Slot` 的内容并创建对应的 `FNameEntry`
|
|
|
+
|
|
|
+#### CreateAndInsertEntry
|
|
|
+
|
|
|
+```cpp
|
|
|
+template<class EntryScopeLock>
|
|
|
+FNameEntryId CreateAndInsertEntry(FNameSlot& Slot, const FNameValue<Sensitivity>& Value)
|
|
|
+{
|
|
|
+ FNameEntryId NewEntryId = Entries->Create<EntryScopeLock>(Value.Name, GetExistingComparisonId(Value), Value.Hash.EntryProbeHeader);
|
|
|
+
|
|
|
+ // 判断 Slots 容量是否超过一定比例(9/10)
|
|
|
+ ClaimSlot(Slot, FNameSlot(NewEntryId, Value.Hash.SlotProbeHash));
|
|
|
+
|
|
|
+ ++NumCreatedEntries;
|
|
|
+ NumCreatedWideEntries += Value.Name.bIsWide;
|
|
|
+
|
|
|
+ return NewEntryId;
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+通过 `Entries->Create` 创建 `FNameEntry` 实体,并设置 `Block` 和 `Offset` 得到 `FNameEntry` 对应的 `FNameEntryHandle`
|
|
|
+
|
|
|
+`ClaimSlot` 就是判断容器占用是否超过 `9/10` 超过了就扩容
|
|
|
+
|
|
|
+> 使用 `UsedSlots * LoadFactorDivisor > LoadFactorQuotient * Capacity()` 是因为除法性能消耗比乘法大得多
|
|
|
+
|
|
|
+### FNameEntryAllocator
|
|
|
+
|
|
|
+```cpp
|
|
|
+class FNameEntryAllocator
|
|
|
+{
|
|
|
+public:
|
|
|
+ enum { Stride = alignof(FNameEntry) };
|
|
|
+ enum { BlockSizeBytes = Stride * FNameBlockOffsets };、
|
|
|
+
|
|
|
+ // some functions ...
|
|
|
+
|
|
|
+private:
|
|
|
+ mutable FRWLock Lock;
|
|
|
+ uint32 CurrentBlock = 0;
|
|
|
+ uint32 CurrentByteCursor = 0;
|
|
|
+ uint8* Blocks[FNameMaxBlocks] = {};
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+- `Stride` 步长,也就是一个 `FNameEntry` 的大小
|
|
|
+- `BlockSizeBytes` 一个 `Block` 的大小,`FNameBlockOffsets` 是 $2^16$ 也就是 `65536` 字节
|
|
|
+- `FNameMaxBlocks` 值为 $2^13$ 也就是 8192,所以说最多 8192 个 `Block` 区块
|
|
|
+- `CurrentBlock` 当前所属**区块**的序号
|
|
|
+- `CurrentByteCursor` 当前**区块**的偏移位置,也就是空内存的起点
|
|
|
+
|
|
|
+在 `Allocate` 函数中,可以观察到
|
|
|
+
|
|
|
+1. 如果当前**区块**不足以塞下新的 `FNameEntry` 的话,就会创建一个新的区块,并将 `CurrentByteCursor` 归零
|
|
|
+2. 将 `CurrentByteCursor` 指向空白内存的首地址
|
|
|
+3. 将当前区块、偏移量作为参数传递给 `FNameEntryHandle`,未来可以直接通过这两个值索引到对应内存
|
|
|
+
|
|
|
+```cpp
|
|
|
+Bytes = Align(Bytes, alignof(FNameEntry));
|
|
|
+
|
|
|
+if (BlockSizeBytes - CurrentByteCursor < Bytes)
|
|
|
+{
|
|
|
+ AllocateNewBlock();
|
|
|
+ AlignCurrentByteCursor<bNumbered>();
|
|
|
+}
|
|
|
+
|
|
|
+uint32 ByteOffset = CurrentByteCursor;
|
|
|
+CurrentByteCursor += Bytes;
|
|
|
+
|
|
|
+return FNameEntryHandle(CurrentBlock, ByteOffset / Stride);
|
|
|
+```
|
|
|
+
|
|
|
+
|
|
|
+### FNamePool
|
|
|
+
|
|
|
+首先 `FName` 都存储在 `FNamePool` 这个结构体中
|
|
|
+
|
|
|
+```cpp
|
|
|
+class FNamePool
|
|
|
+{
|
|
|
+ // ... functions
|
|
|
+
|
|
|
+private:
|
|
|
+ enum { MaxENames = 512 };
|
|
|
+
|
|
|
+ FNameEntryAllocator Entries;
|
|
|
+
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+ FNamePoolShard<ENameCase::CaseSensitive> DisplayShards[FNamePoolShards];
|
|
|
+#endif
|
|
|
+ FNamePoolShard<ENameCase::IgnoreCase> ComparisonShards[FNamePoolShards];
|
|
|
+
|
|
|
+ // some else property
|
|
|
+};
|
|
|
+```
|
|
|
+
|
|
|
+`FNamePoolShards` 的值是 1024,这是定义在全局变量中的,所以说一开始就定义了一个 `FNamePoolShard` 数组,内容是 1024 个
|
|
|
+
|
|
|
+`FNameEntryAllocator` 就是一个内存分配器
|
|
|
+
|
|
|
+#### Store 存储
|
|
|
+
|
|
|
+```cpp
|
|
|
+FNameEntryId FNamePool::Store(FNameStringView Name)
|
|
|
+{
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+ // 大小写敏感的做法
|
|
|
+#endif
|
|
|
+
|
|
|
+ bool bAdded = false;
|
|
|
+
|
|
|
+ // Insert comparison name first since display value must contain comparison name
|
|
|
+ FNameComparisonValue ComparisonValue(Name);
|
|
|
+ FNameEntryId ComparisonId = ComparisonShards[ComparisonValue.Hash.ShardIndex].Insert(ComparisonValue, bAdded);
|
|
|
+
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+ DisplayValue.ComparisonId = ComparisonId;
|
|
|
+ return StoreValue(DisplayValue, bAdded).ToDisplayId();
|
|
|
+#else
|
|
|
+ return ComparisonId;
|
|
|
+#endif
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+`FNamePool::Store` 是一个用于存储一个 `FName` 的函数,通过传入 `Name` 创建一个 `FNameComparisonValue` 的对象
|
|
|
+
|
|
|
+从这个函数调用堆栈可以确定 `FNamePool` 的内存结构
|
|
|
+
|
|
|
+```cpp
|
|
|
+using FNameComparisonValue = FNameValue<ENameCase::IgnoreCase>;
|
|
|
+#if WITH_CASE_PRESERVING_NAME
|
|
|
+using FNameDisplayValue = FNameValue<ENameCase::CaseSensitive>;
|
|
|
+#endif
|
|
|
+```
|
|
|
+
|
|
|
+通过 `ComparisonShards[ComparisonValue.Hash.ShardIndex]` 得到 `FNamePoolShard`,并向其添加值
|
|
|
+
|
|
|
+`ComparisonValue.Hash.ShardIndex` 的 `ShardIndex` 还记得是什么吗?
|
|
|
+
|
|
|
+`ShardIndex` 是通过 `CityHash64` 计算得到的 `Hash` 值的高 32 位中的低 10 位,取值范围是 0~1023
|
|
|
+
|
|
|
+刚好 `ComparisonShards` 的大小也是 1024,索引范围是 0~1023
|
|
|
+
|
|
|
+其实 `FNamePool` 就是这么设计的,目的就是通过 `Hash` 值进行分区,定义 `FNamePoolShard` 数组作为一级索引
|
|
|
+
|
|
|
+找到 `FNamePoolShard` 之后,调用其 `Insert` 函数,创建 Entry 并保存到对应的 `Slot` 中
|
|
|
+
|
|
|
+## 总结
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
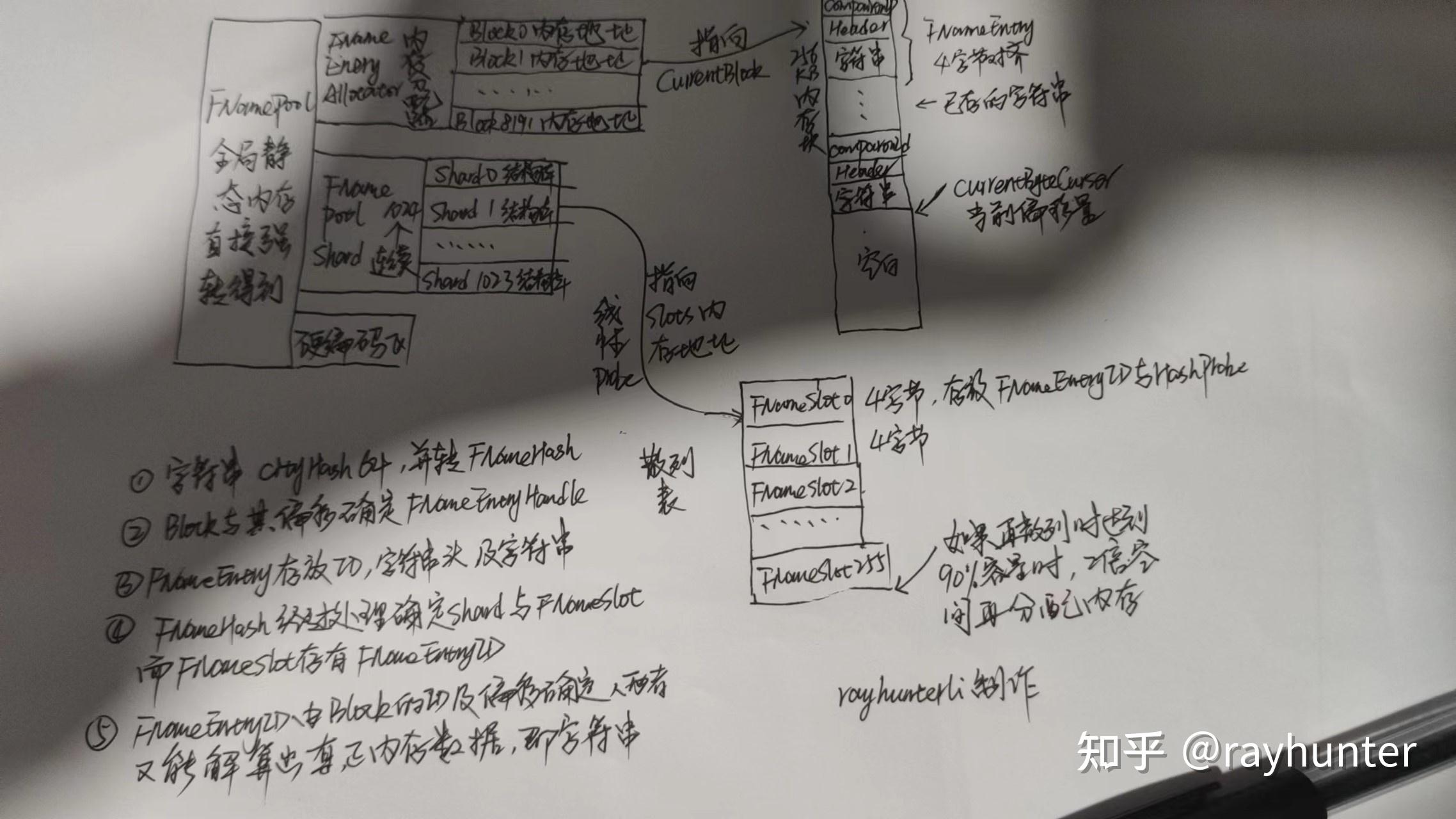
+> 大哥画图很清晰了
|
|
|
+
|
|
|
+`FName` 的存储结构是从 `FNamePool` 为起点
|
|
|
+
|
|
|
+`FNamePool` 分成两块
|
|
|
+
|
|
|
+1. `FNameEntryAllocator` 用于存储真正的内容,并管理内存,可以通过**区块**序号和**偏移量**来得到具体的 `FNameEntry` 值
|
|
|
+2. `ComparisonShards` 存储一系列的 **Slot**
|
|
|
+ - 通过 `FNameSlot` 可以得到 `FNameEntryId`
|
|
|
+ - 通过 `FNameEntryId` 可以得到 `FNameEntryHandle`
|
|
|
+ - 通过 `FNameEntryHandle` 可以得到**区块序号**和**偏移量**
|
|
|
+
|
|
|
+添加过程很简单清楚
|
|
|
+
|
|
|
+1. 将字符串经过 `CityHash64` 得到 64 位数字 `Hash` 值
|
|
|
+2. 通过 `Hash` 值的高 32 位的低 10 位可以找到 `FNamePool::ComparisonShards` 数组中的一个 `FNamePoolShard`
|
|
|
+3. 通过 `Hash` 值计算得到 `Probe`,对 `FNamePoolShard::Slots` 数组进行遍历查找
|
|
|
+ - 首先通过 `Probe` 值进行粗筛选
|
|
|
+ - 在通过 `Header` 进行字符长度相等判断
|
|
|
+ - 最后逐字符相等判断
|
|
|
+4. 如果没有则创建 `FNameEntry`
|
|
|
+ - 将创建的 `FNameEntry` 的 **区块序号** 和 **偏移值** 构建成 `FNameEntryHandle`
|
|
|
+ - 将 `FNameEntryHandle` 转换成 `FNameEntryId`
|
|
|
+ - 最后得到 `FNameEntryId`
|

 liucong5
liucong5
{kind=link}